上传数据集
Hub 汇集了大量由社区和研究者整理的数据集。我们鼓励你将数据集分享至 Hub,壮大 ML 社区、让所有人受益。所有贡献都非常欢迎——上传数据集只需轻轻一拖!
如果你还没有账号,请先注册 Hugging Face Hub。
使用 Hub 界面上传
Hub 的网页界面让没有开发经验的用户也能轻松上传数据集。
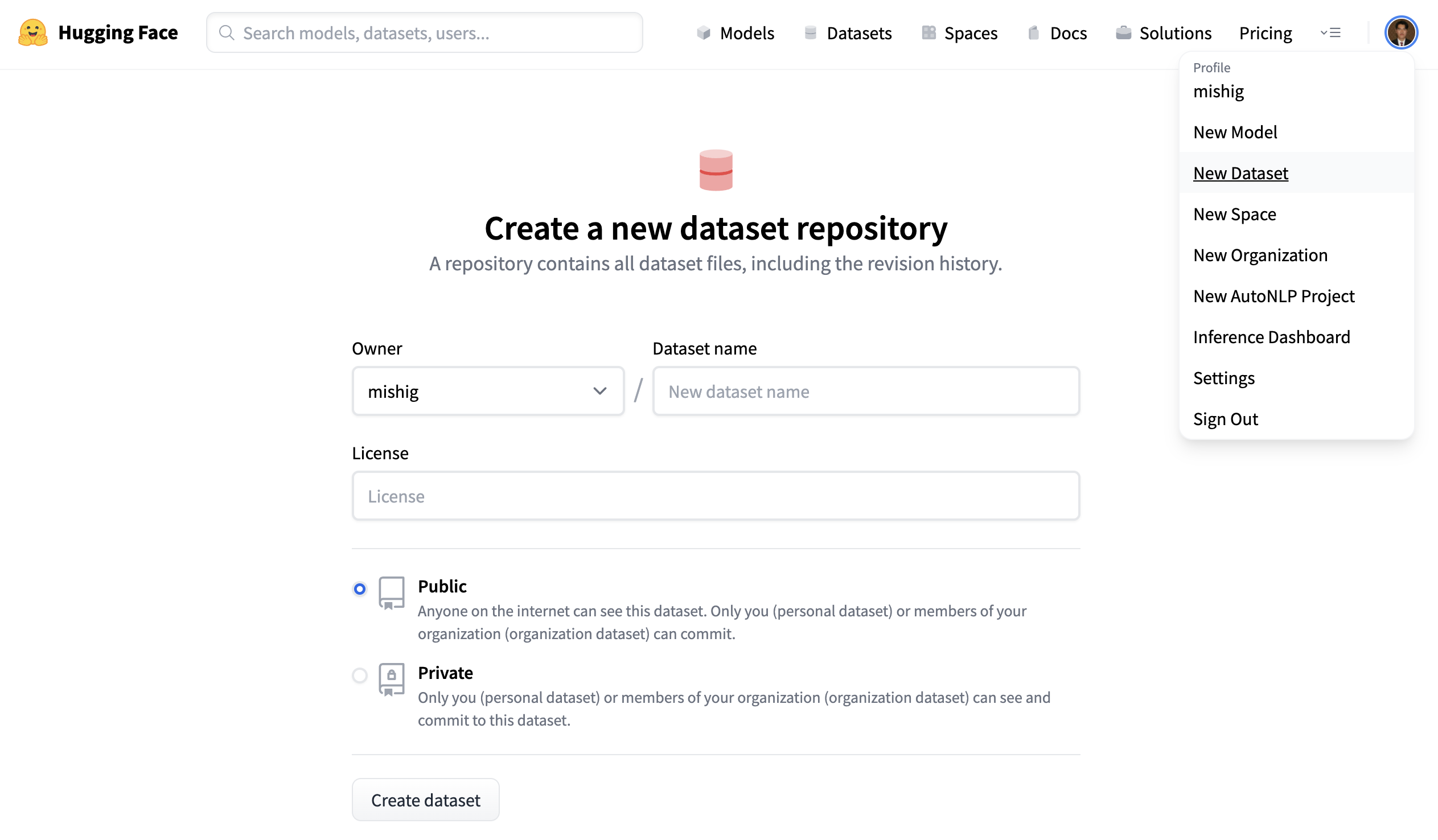
创建仓库
仓库会托管你的全部数据集文件及其版本历史,便于保留多个版本。
- 点击头像并选择 New Dataset,创建新的数据集仓库。
- 为数据集取名,并选择公开或私有。公开数据集对所有人可见,私有数据集仅你或组织成员可访问。
上传数据集
- 创建仓库后,进入 Files and versions 标签页添加文件。点击 Add file 上传数据集文件。我们支持多种文本、音频、图像等数据格式,如
.csv、.mp3��、.jpg(完整列表见文件格式)。
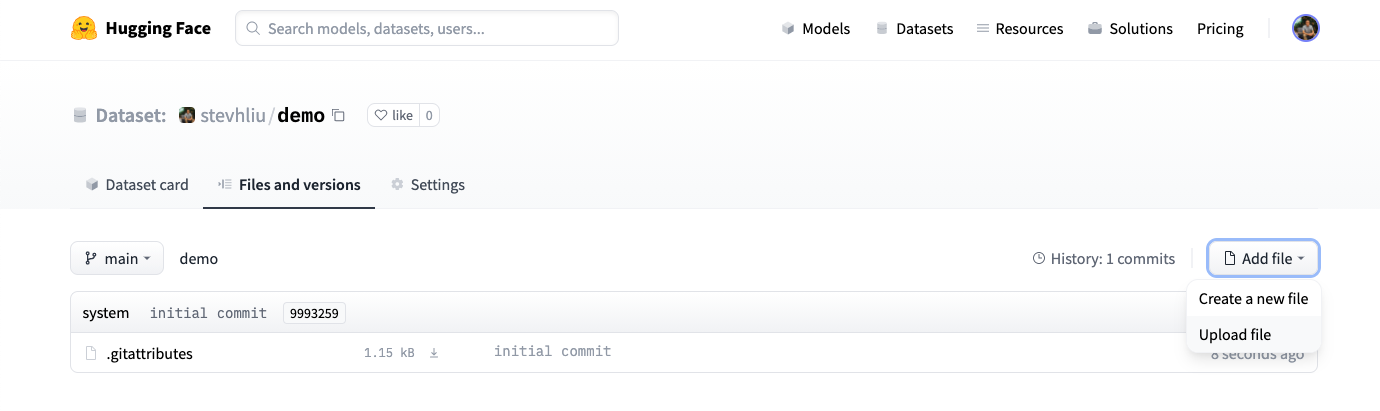
- 将数据集文件拖放到页面中。
- 上传完成后,数据集文件会存储在仓库中。
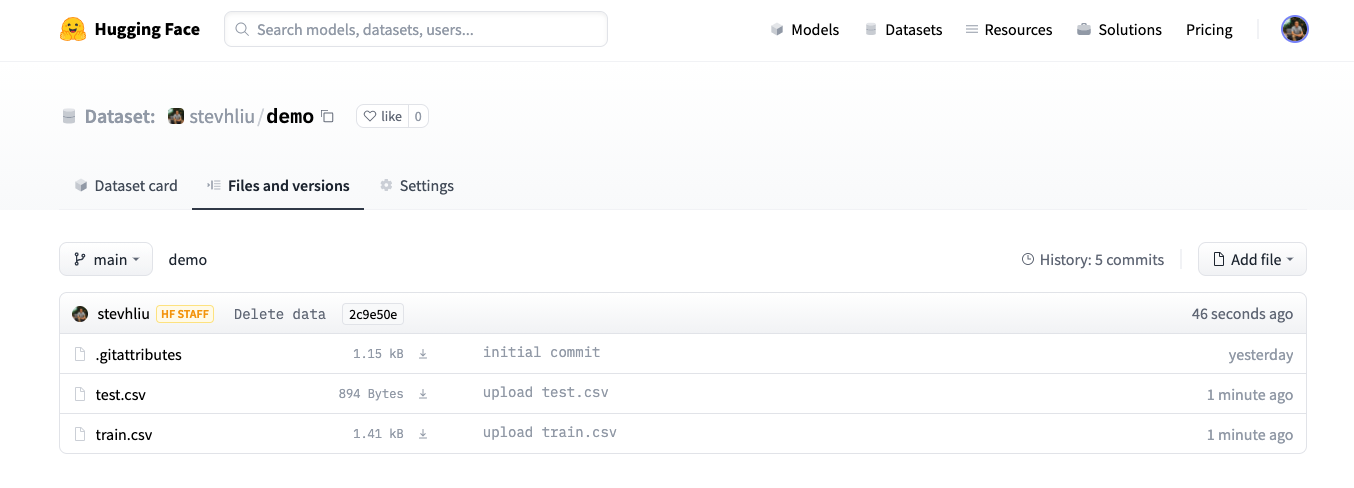
创建数据集卡片
数据集卡片对于帮助用户发现并正确使用数据集至关重要。
- 点击 Create Dataset Card 创建数据集卡片。此按钮会在仓库中生成
README.md文件。
-
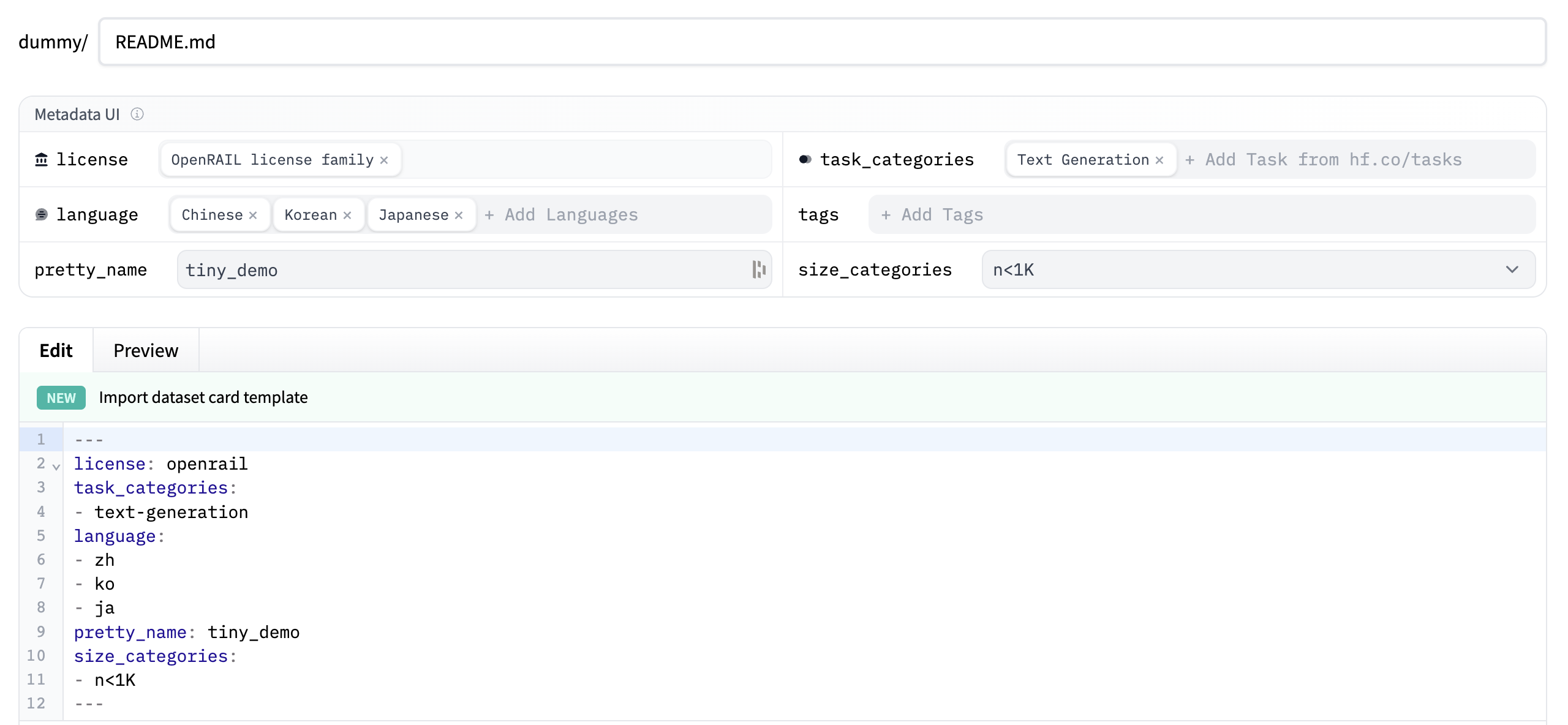
页面顶部显示 Metadata UI,提供许可证、语言、任务类别等字段。这些是帮助用户在 Hub 上发现数据集的重要标签(若适用)。当你为字段选择某个值后,标签会自动写入卡片顶部。
你也可以参考数据集卡片规范,其中列出了所有可用标签,包括
annotations_creators等可选字段,帮助你挑选适合的数据。
-
在数据集卡片中撰写文档,向社区介绍数据集内容:适用场景、局限性、数据来源、伦理考量等。
你可以点击编辑器顶部的 Import dataset card template 链接,自动生成卡片模板。有关优质卡片的示例,可参考 CNN DailyMail 数据集卡片。
使用 huggingface_hub 客户端库
huggingface_hub 库提供丰富功能,支持管理仓库、创建仓库并上传数据集。更多信息请查看客户端库文档。
使用其他库
部分库(如 🤗 Datasets、Pandas、Polars、Dask、DuckDB、Daft) 也支持将文件上传至 Hub。更多详情请参阅数据集 Hub 支持的库列表。
使用 Git
数据集仓库本质上是 Git 仓库,你可以用 Git 将数据文件推送到 Hub。请参阅仓库快速入门,了解如何使用 git CLI 提交并推送数据集。
文件格式
Hub 原生支持多种文件格式:
- Parquet (.parquet)
- CSV (.csv, .tsv)
- JSON Lines、JSON (.jsonl, .json)
- Arrow 流式格式 (.arrow)
- 文本 (.txt)
- 图像 (.png, .jpg 等)
- 音频 (.wav, .mp3 等)
- PDF (.pdf)
- WebDataset (.tar)
同时支持 ZIP (.zip)、GZIP (.gz)、ZSTD (.zst)、BZ2 (.bz2)、LZ4 (.lz4)、LZMA (.xz) 压缩文件。
图像与音频文件还可以附带元数据文件。关于图像与音频数据的结构,请参阅数据文件配置以及 示例数据集集合,其中包含 CSV、TSV、图像等示例。
如需充分利用 Hub 功能,建议将文件转换为上述格式;其他格式可能无法被识别。
应选择哪种文件格式?
大多数数据集推荐使用 Parquet,因为其压缩效率高、类型信息丰富,并��且广泛工具支持优化读取和批处理。表格数据也可使用 CSV 或 JSON Lines/JSON(若存在嵌套结构,优先 JSON Lines)。但对于数 GB 以上的数据,Parquet 更合适。图像与音频数据集通常直接上传原始文件即可,便于访问单个文件;若需要大规模流式读取图像或音频,则推荐使用 WebDataset,以避免频繁访问单个文件的开销。若涉及分析、数据筛选或元数据解析等需求,大规模图像与音频数据集仍建议使用 Parquet。
Data Studio
Data Studio 有助于在下载前了解数据实际内容。所有公共数据集默认启用;若为私有数据集,只要由 PRO 用户或团队/企业组织拥有,也可使用。
上传数据集后,请确认数据集查看器是否正确显示数据,或配置数据集查看器。
大规模数据集
Hugging Face Hub 支持大规模数据集,通常以 Parquet(例如通过 🤗 Datasets 的 push_to_hub())或 WebDataset 格式上传。
你可以利用 huggingface_hub 库高速上传大型数据集。