WebDataset
WebDataset 是一个用于编写大型数据集 I/O 管道的库。 其顺序 I/O 和分片功能使其特别适用于将大规模数据集流式传输到 DataLoader。
WebDataset 格式
WebDataset 文件是一个包含一系列数据文件的 TAR 归档文件。 所有具有相同前缀的连续数据文件被视为同一示例的一部分(例如,图像/音频文件及其标签或元数据):


标签和元数据可以在 .json 文件中,在 .txt 文件中(用于标题、描述),或在 .cls 文件中(用于类别索引)。
大规模 WebDataset 由许多称为分片的文件组成,其中每个分片是一个 TAR 归档文件。 每个分片通常约为 1GB,但完整数据集可能达到数 TB!
多模态支持
WebDataset 专为多模态数据集设计,即用于图像、音频和/或视频数据集。
实际上,由于媒体文件往往相当大,WebDataset 的顺序 I/O 支持大读取和缓冲,从而实现最佳的数据加载速度。
以下是支持的数据格式的非详尽列表:
- 图像:jpeg、png、tiff
- 音频:mp3、m4a、wav、flac
- 视频:mp4、mov、avi
- 其他:npy、npz
完整列表会随时间演变,并取决于实现。例如,你可以在源代码这里找到 webdataset 包支持哪些格式。
流式传输
流式传输 TAR 归档文件很快,因为它读取连续的数据块。 它可能比逐个读取单独的数据文件快几个数量级。
WebDataset 流式传输在从磁盘和云存储读取时都提供高速性能,这使其成为馈送到 DataLoader 的理想格式:
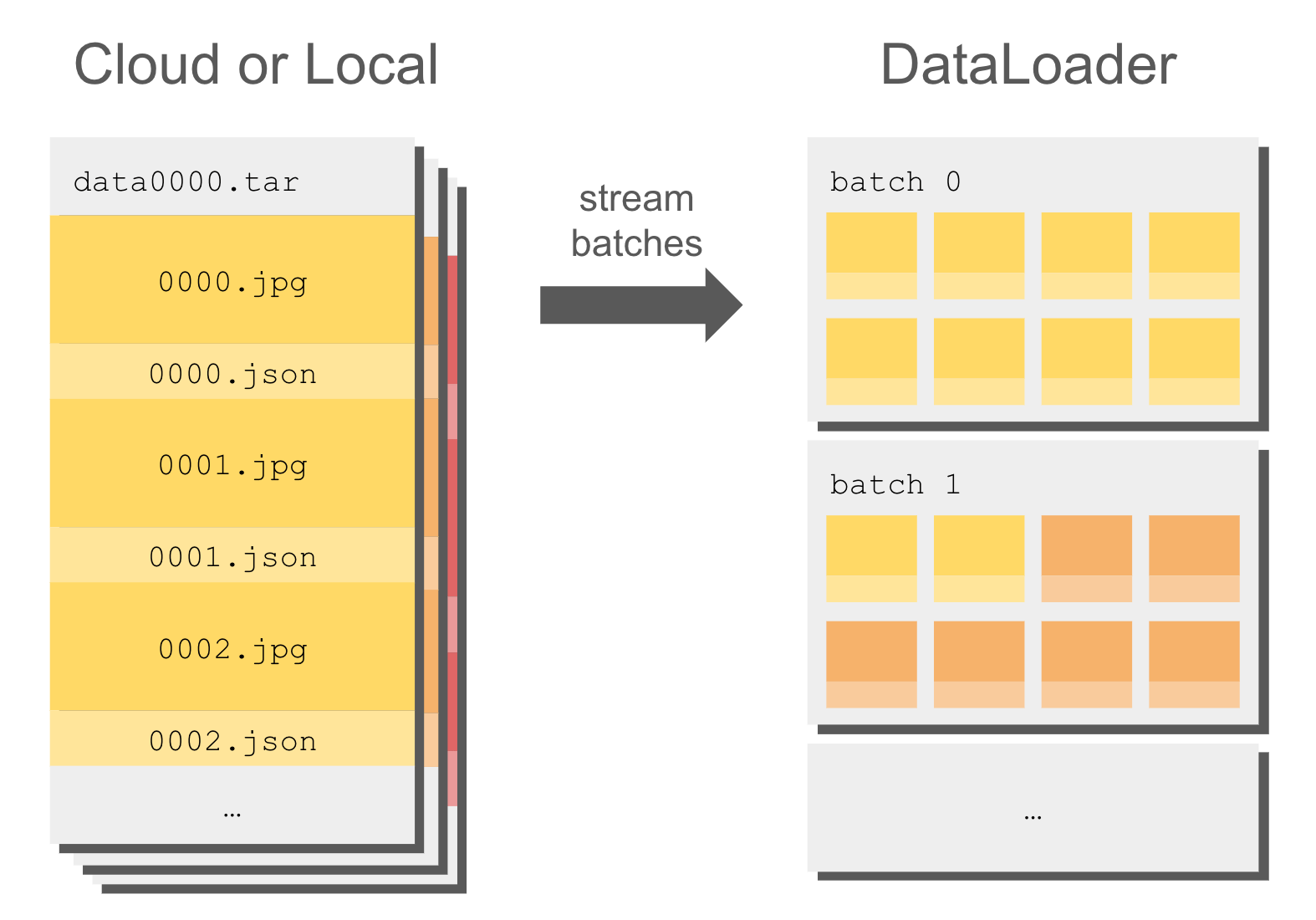
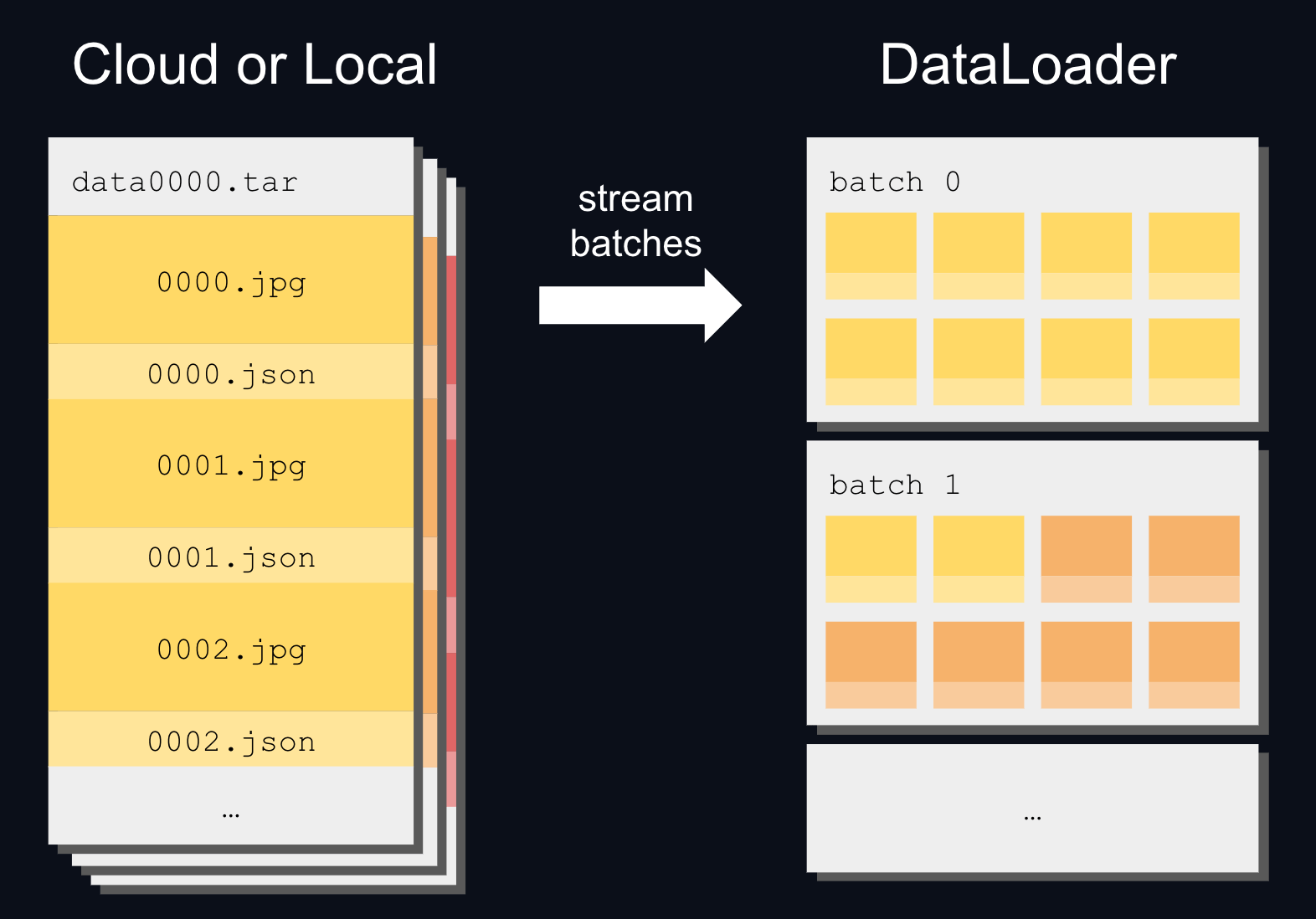
例如,以下是如何直接从 Hugging Face 流式传输 timm/imagenet-12k-wds 数据集:
首先,你需要使用你的 Hugging Face 账户登录,例如使用:
hf auth login
然后,你可以使用 WebDataset 流式传输数据集:
>>> import webdataset as wds
>>> from huggingface_hub import get_token
>>> from torch.utils.data import DataLoader
>>> hf_token = get_token()
>>> url = "https://huggingface.co/datasets/timm/imagenet-12k-wds/resolve/main/imagenet12k-train-{{0000..1023}}.tar"
>>> url = f"pipe:curl -s -L {url} -H 'Authorization:Bearer {hf_token}'"
>>> dataset = wds.WebDataset(url).decode()
>>> dataloader = DataLoader(dataset, batch_size=64, num_workers=4)
打乱
通常,WebDataset 格式的数据集已经打乱并准备好馈送到 DataLoader。 �但你仍然可以使用 WebDataset 的近似打乱来重新打乱数据。
除了打乱分片列表外,WebDataset 还使用缓冲区来打乱数据集,而不会影响速度:
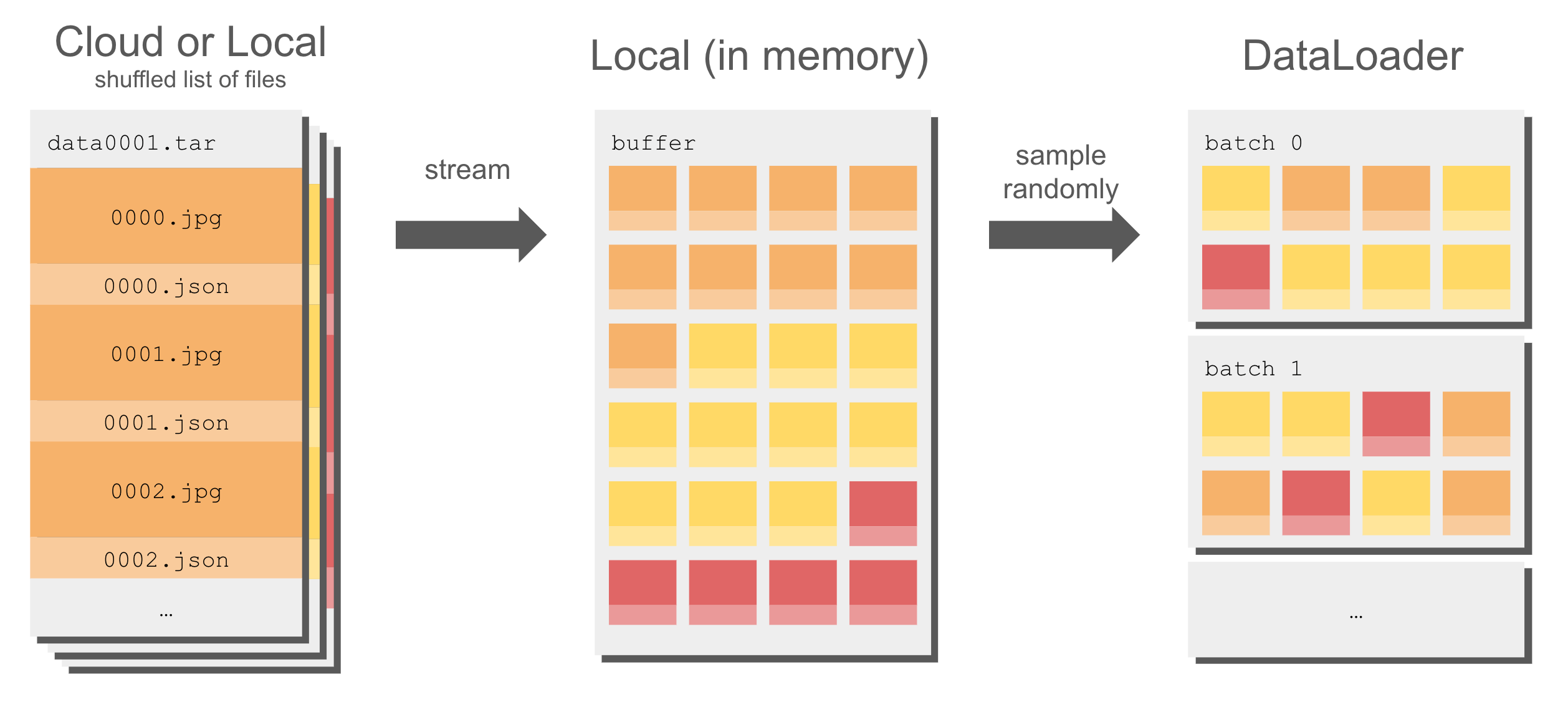
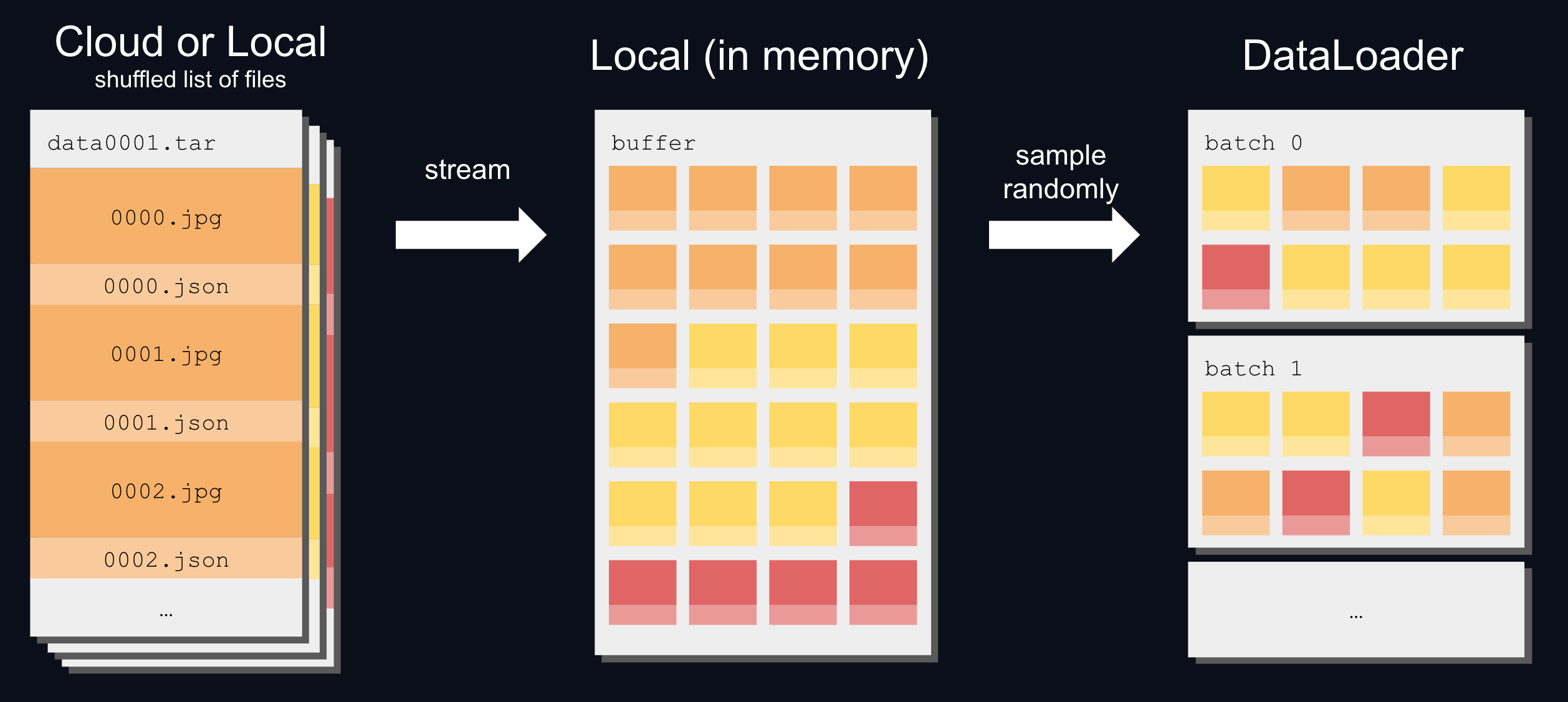
要打乱分片文件列表并从打乱缓冲区中随机采样:
>>> buffer_size = 1000
>>> dataset = (
... wds.WebDataset(url, shardshuffle=True)
... .shuffle(buffer_size)
... .decode()
... )