模型卡片
什么是模型卡片?
模型卡片是伴随模型的文件,�提供有用的信息。实际上,模型卡片是带有额外元数据的简单 Markdown 文件。模型卡片对于可发现性、可重现性和共享至关重要!你可以在任何模型仓库中找到作为 README.md 文件的模型卡片。
模型卡片应描述:
- 模型本身
- 其预期用途和潜在局限性,包括偏见和伦理考量,详见 Mitchell, 2018
- 训练参数和实验信息(你可以嵌入或链接到实验跟踪平台以供参考)
- 用于训练模型的数据集
- 模型的评估结果
模型卡片模板可在此处获取。
如何填写模型卡片的每个部分,请参阅带注释的模型卡片。
Hub 上的模型卡片有两个关键部分,信息有所重叠:
模型卡片元数据
模型仓库会将其 README.md 渲染为模型卡片。模型卡片是一个 Markdown 文件,顶部有一个 YAML 部分,包含关于模型的元数据。
你添加到模型卡片中的元数据有助于发现和更轻松地使用你的模型。例如:
- 允许用户在 https://huggingface.co/models 上筛选模型。
- 显示模型的许可证。
- 在元数据中添加数据集会在你的模型页面上添加一条消息,显示
Datasets used to train:并链接相关数据集(如果它们在 Hub 上可用)。
数据集、指标和语言标识符是在数据集、指标和语言页面上列出的那些。
向模型卡片添加元数据
有几种不同的方式可以向模型卡片添加元数据,包括:
- 使用元数据 UI
- 直接编辑
README.md文件的 YAML 部分 - 通过
huggingface_hubPython 库,详见文档。
许多具有 Hub 集成的库在你上传模型时会自动向模型卡片添加元数据。
使用元数据 UI
你可以使用元数据 UI 向模型卡片添加元数据。要访问元数据 UI,请转到模型页面,然后点击模��型卡片右上角的 Edit model card 按钮。这将打开一个编辑器,显示模型卡片 README.md 文件,以及用于编辑元数据的 UI。
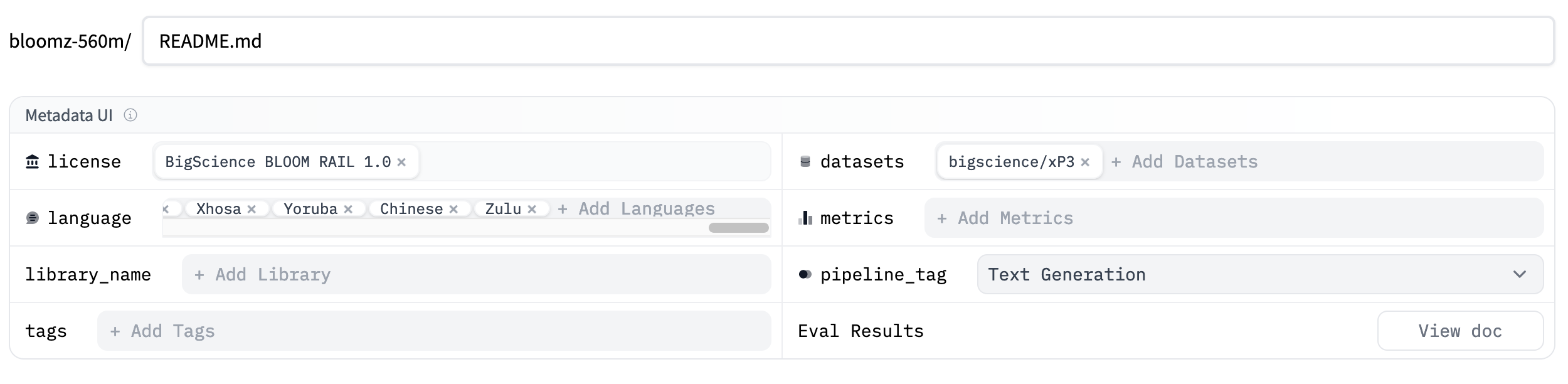
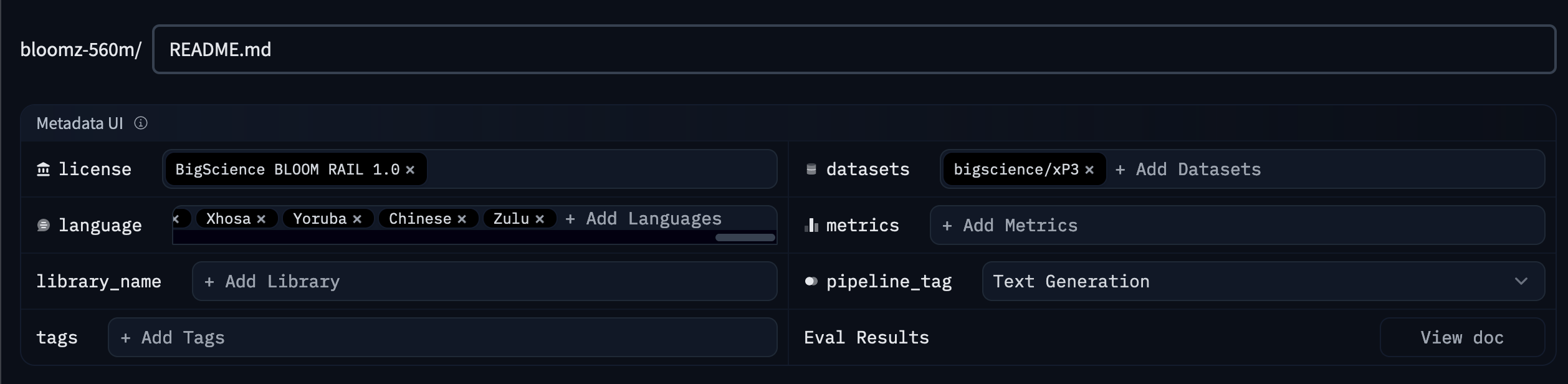
此 UI 允许你向模型卡片添加关键元数据,许多字段会根据你提供的信息自动完成。使用 UI 是向模型卡片添加元数据的最简单方法,但它不支持所有元数据字段。如果你想添加 UI 不支持的元数据,可以直接编辑 README.md 文件的 YAML 部分。
编辑 README.md 文件的 YAML 部分
你也可以直接编辑 README.md 文件的 YAML 部分。如果模型卡片还没有 YAML 部分,你可以在文件顶部添加三个 ---,然后包含所有相关元数据,并用另一组 --- 关闭该部分,如下例所示:
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
base_model: "base model Hub identifier"
---
你可以在此处找到详细的模型卡片元数据规范:此处。
指定库
你可以在模型卡片元数据部分指定支持的库。有关我们支持的库的更多信息,请参阅此处。库将按以下优先级顺序指定:
- 在模型卡片中指定
library_name(如果你的模型不是transformers模型,建议使用此方法)。可以通过元数据 UI 或直接在模型卡片 YAML 部分添加此信息:
library_name: flair
- 使用支持的库名称作为标签
tags:
- flair
如果未指定,Hub 将尝试自动检测库类型。但是,不鼓励使用这种方法,仓库创建者应尽可能使用显式的 library_name。
- 通过检查是否存在
*.nemo或*.mlmodel等文件,Hub 可以确定模型是否来自 NeMo 或 CoreML。 - 过去,如果未检测到任何内容且存在
config.json文件,则假定库为transformers。对于 2024 年 8 月之后创建的模型仓库,情况已不再如此——因此你需要显式指定library_name: transformers。
指定基础模型
如果你的模型是基础模型的微调版本、适配器或量化版本,你可以在模型卡片元数据部分指定基础模型。此信息也可用于指示你的模型是否是多个现有模型的合并。因此,base_model 字段可以是单个模型 ID,也可以是一个或多个基础模型的列表(由其 Hub 标识符指定)。
base_model: HuggingFaceH4/zephyr-7b-beta
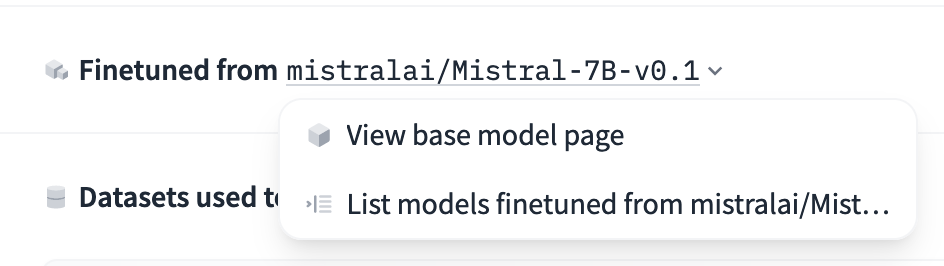
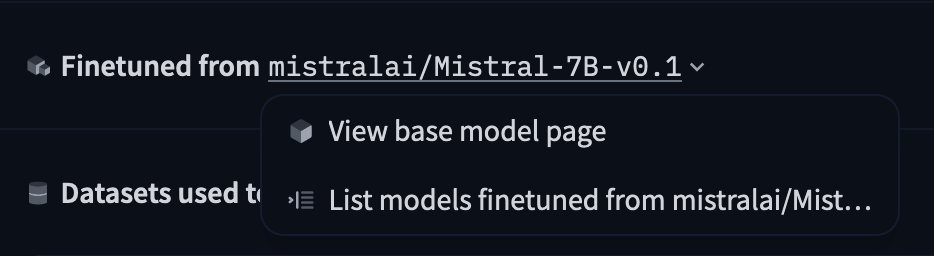
此元数据将用于在模型页面上显示基础模型。用户还可以使用此信息按基础模型筛选模型,或查找源自特定基础模型的模型:
对于微调模型:
对于适配器(LoRA、PEFT 等):
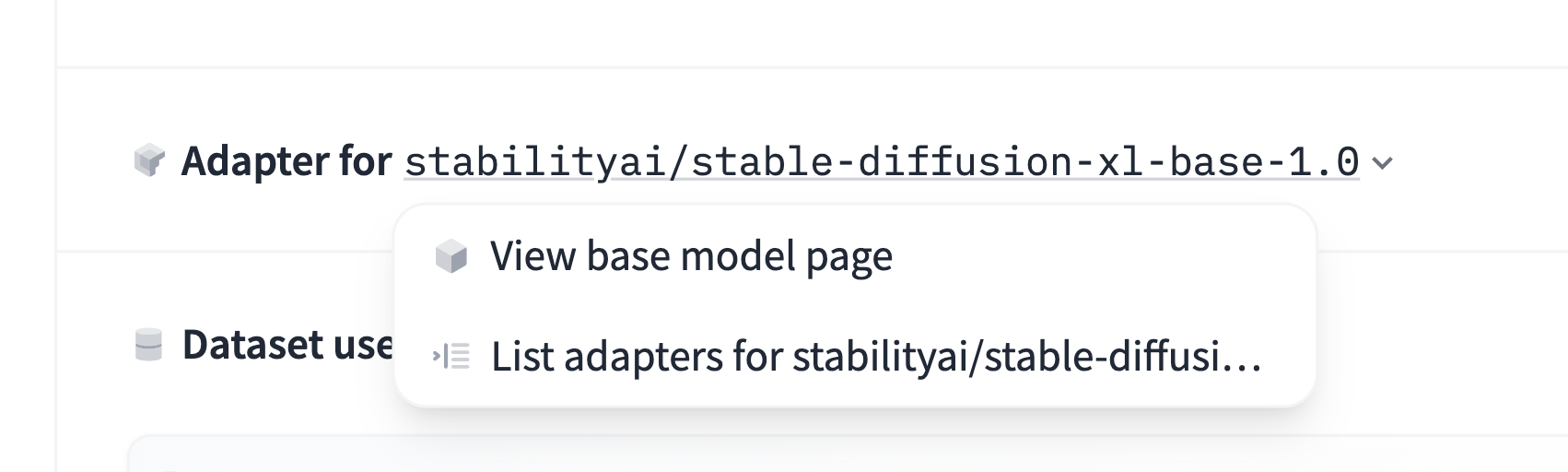
对于另一个模型的量化版本:
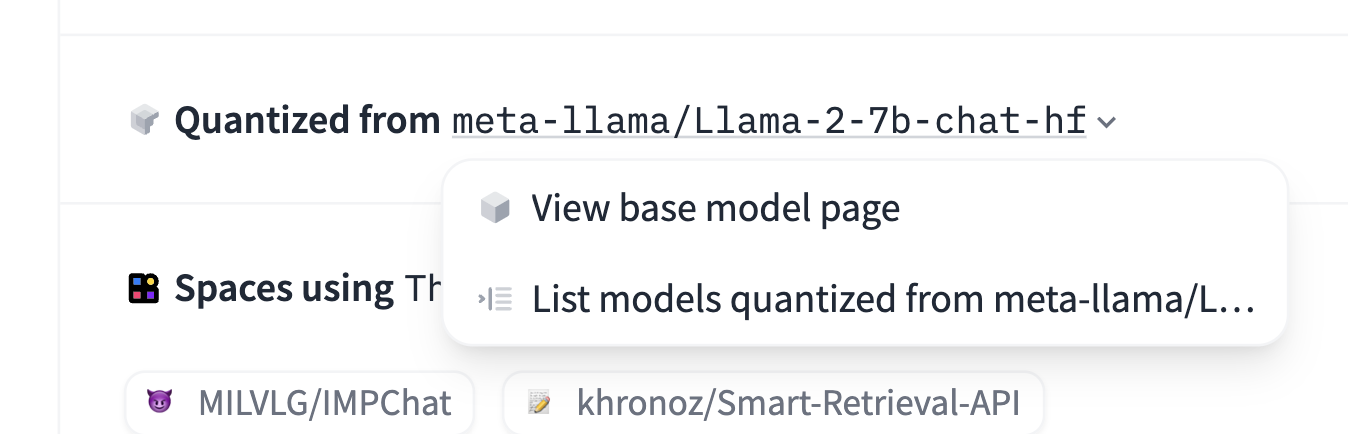

对于两个或多个模型的合并:
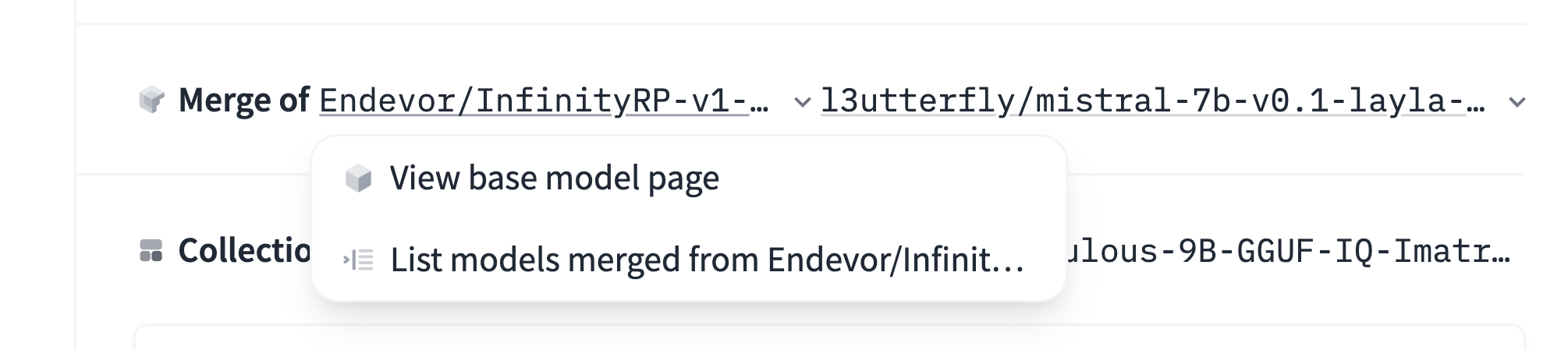
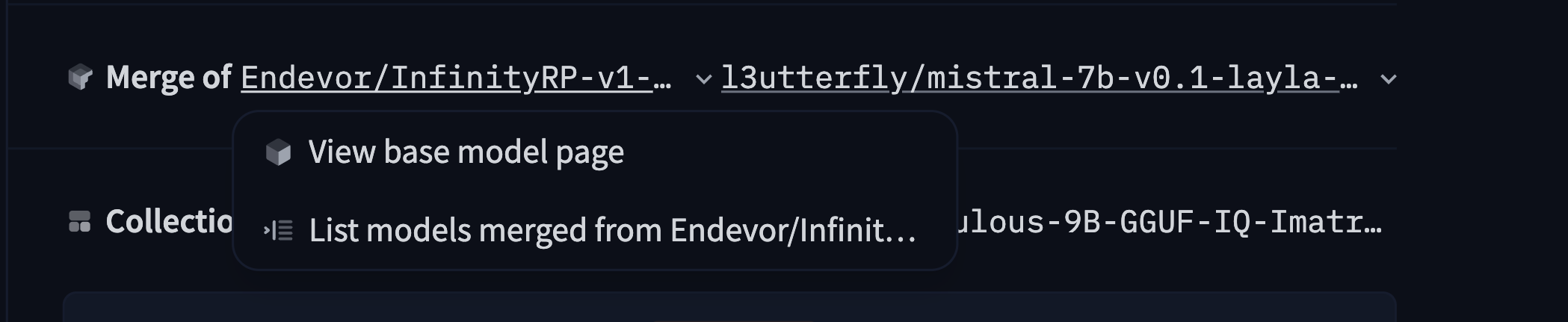
在合并的情况下,你指定两个或多个基础模型的列表:
base_model:
- Endevor/InfinityRP-v1-7B
- l3utterfly/mistral-7b-v0.1-layla-v4
Hub 将从当前模型推断到基础模型的关系类型("adapter"、"merge"、"quantized"、"finetune"),但你也可以根据需要显式设置:例如 base_model_relation: quantized。
指定新版本
如果你的模型在 Hub 上有新版本可用,你可以在 new_version 字段中指定它。
例如,在 l3utterfly/mistral-7b-v0.1-layla-v3 上:
new_version: l3utterfly/mistral-7b-v0.1-layla-v4
此元数据将用于在模型页面上显示指向模型最新版本的链接。如果 new_version 中链接的模型也有 new_version 字段,则始终会显示最新版本。


指定数据集
你可以在模型卡片元数据部分指定用于训练模型的数据集。数据集将显示在模型页面上,用户将能够按数据集筛选模型。你应该使用 Hub 数据集标识符,它与数据集的仓库名称相同:
datasets:
- imdb
- HuggingFaceH4/no_robots
指定任务(pipeline_tag)
你可以在模型卡片元数据中指定 pipeline_tag。pipeline_tag 指示模型用于的任务类型。此标签将显示在模型页面上,用户可以在 Hub 上按任务筛选模型。此标签还用于确定模型使用哪个小部件以及底层使用哪些 API。
对于 transformers 模型,管道标签会自动从模型的 config.json 文件推断,但你可以根据需要在模型卡片元数据中覆盖它。在元数据 UI 中编辑此字段将确保管道标签有效。其他一些具有 Hub 集成的库也会自动将管道标签添加到模型卡片元数据中。
指定许可证
你可以在模型卡片元数据部分指定许可证。许可证将显示在模型页面上,用户将能够按许可证筛选模型。使用元数据 UI 时,你将看到最常见许可证的下拉列表。
如果需要,你还可以通过将 other 添加为许可证值并在元数据中指定名称和许可证链接来指定自定义许可证。
# 示例来自 https://huggingface.co/coqui/XTTS-v1
---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
---
如果许可证无法通过 URL 获取,你可以链接到存储在模型仓库中的 LICENSE 文件。
评估结果
你可以以结构化方式在模型卡片元数据中指定模型的评估结果。结果由 Hub 解析并显示在模型页面上的小部件中。以下是 bigcode/starcoder 模型的示例:
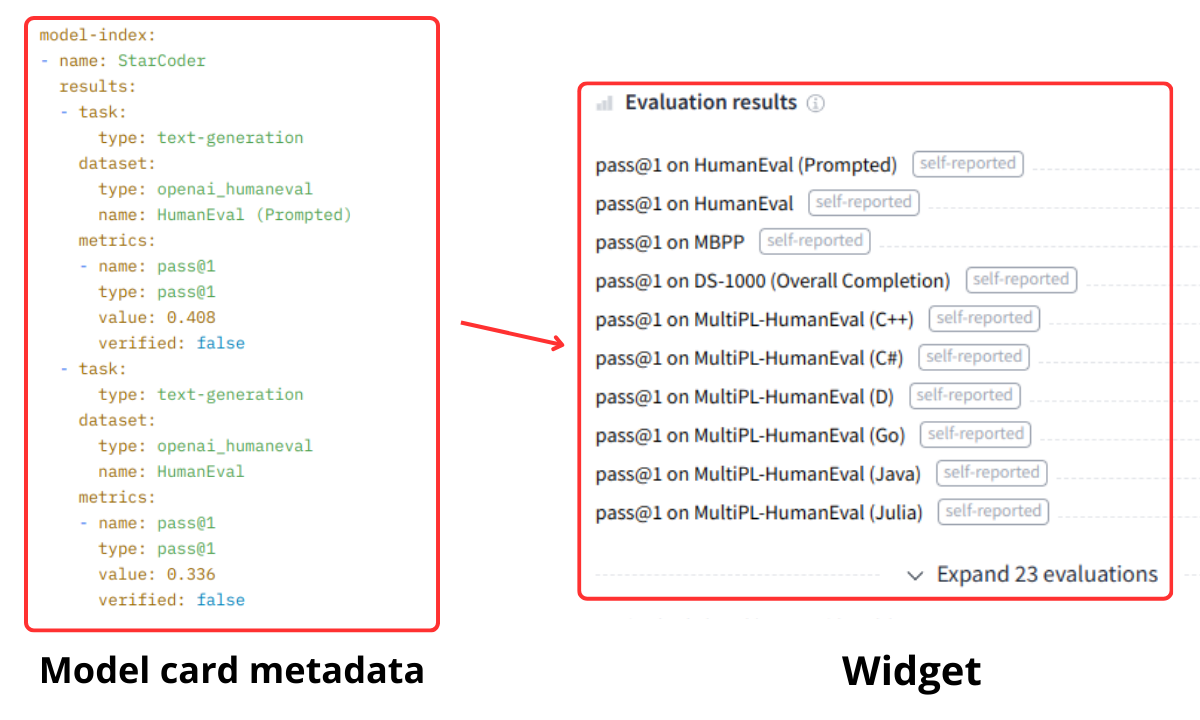

元数据规范基于 Papers with Code 的模型索引规范。这使我们能够在适当时直接将结果索引到 Papers with Code 的排行榜中。你还可以链接计算评估结果的来源。
以下是一个部分示例,描述 01-ai/Yi-34B 在 ARC 基准测试中的得分。结果来自Open LLM Leaderboard,它被定义为 source:
---
model-index:
- name: Yi-34B
results:
- task:
type: text-generation
dataset:
name: ai2_arc
type: ai2_arc
metrics:
- name: AI2 Reasoning Challenge (25-Shot)
type: AI2 Reasoning Challenge (25-Shot)
value: 64.59
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
---
有关如何格式化此数据的更多详细信息,请查看模型卡片规范。
CO2 排放
模型卡片也是展示模型 CO2 影响信息的好地方。访问我们的跟踪和报告 CO2 排放指南以了解更多信息。
链接论文
如果模型卡片包含指向论文页面(在 HF 上或 Arxiv 摘要/PDF)的链接,Hugging Face Hub 将提取 arXiv ID 并将其包含在模型标签中,格式为 arxiv:<PAPER ID>。点击标签将允许你:
- 访问论文页面
- 筛选 Hub 上引用同一论文的其他模型。
有关论文页面的更多信息,请参阅此处。
模型卡片文本
有关如何填写不带 Hub 特定元数据的人类可读模型卡片(以便可以打印、剪切+粘贴等)的详细信息,请参阅带注释的模型卡片。
常见问题
模型标签是如何确定的?
每个模型页面在页面标题中、模型名称下方列出模型的所有标签。这些主要从模型卡片元数据计算得出,尽管有些是自动添加的,如启用小部件中所述。
我可以向模型添加自定义标签吗?
可以,你可以通过将自定义标签添加到模型卡片元数据中的 tags 字段来向模型添加自定义标签。元数据 UI 会建议一些热门标签,但你可以添加任何你想要的标签。例如,你可以通过添加 finance 标签来指示你的模型专注于金融。
如何指示我的模型不适合所有受众
你可以向模型卡片元数据添加 not-for-all-audience 标签。当存在此标签时,模型页面上将显示一条消息,指示该模型不适合所有受众。用户可以点击此消息查看模型卡片。
我可以在模型卡片中编写 LaTeX 吗?
可以!Hub 使用 KaTeX 数学排版库在解析 Markdown 之前在服务器端渲染数学公式。
你必须使用以下分隔符:
$$ ... $$用于显示模式\\(...\\)用于行内模式(斜杠和括号之间没有空格)。
然后你就可以编写:
$$
\LaTeX
$$
$$
\mathrm{MSE} = \left(\frac{1}{n}\right)\sum_{i=1}^{n}(y_{i} - x_{i})^{2}
$$
$$ E=mc^2 $$