首先,什么是上下文窗口(Context Window)?它与在 Cursor 中高效编码有何关联?
从宏观视角来看,大语言模型(LLM)是一种通过海量数据集学习文本模式的人工智能模型,其核心能力是预测和生成文本。这类模型通过理解用户输入,基于历史学习模式提供代码或文本建议,这正是驱动 Cursor 等工具的底层技术。
Token(令牌) 是这些模型的输入与输出单元。它们通常是文本片段(多为单词的组成部分),由 LLM 逐个处理。模型并非一次性读取完整句子,而是基于前序 Token 预测下一个 Token。
若想观察文本如何被 Token 化,可使用 此工具 进行可视化分析。
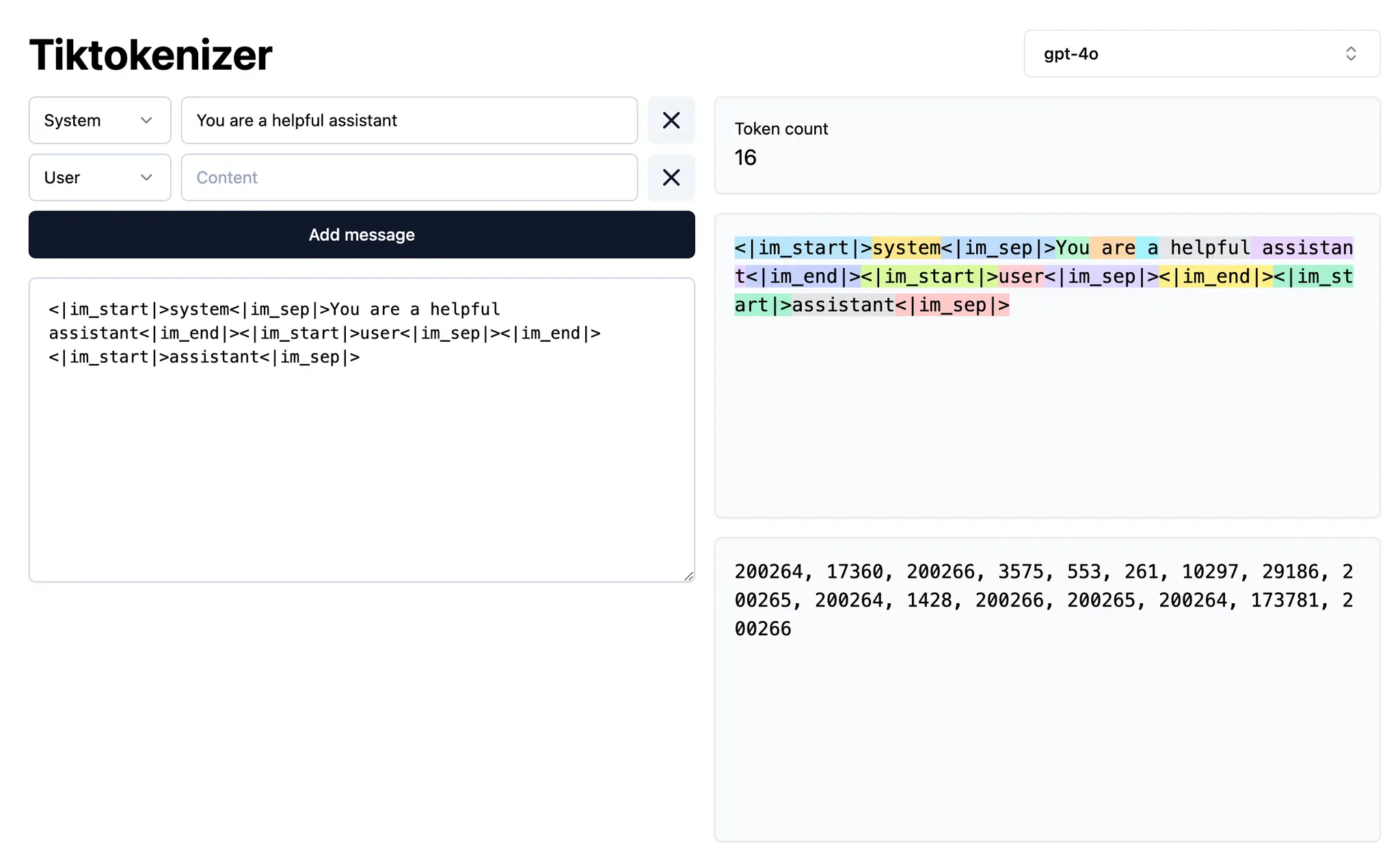
(图示说明:通过 Tokenizer 工具可直观查看文本的分词过程)
什么是上下文?
在 Cursor 中生成代码建议时,"上下文"(context)指的是提供给模型的信息(以"输入令牌"的形式),模型利用这些信息来预测后续内容(以"输出令牌"的形式)。
上下文主要分为两种类型:
- 意图上下文(Intent context):定义用户期望从模型获得的结果。例如,系统提示词通常作为高层次指令,指导模型的行为方式。Cursor 中的大部分"提示词"都属于意图上下文。例如"将按钮颜色从蓝色改为绿色"就是典型的意图陈述,具有指导性。
- 状态上下文(State context):描述当前世界的状态。向 Cursor 提供错误信息、控制台日志、图像和代码片段等都属于状态上下文。这类上下文是描述性的,而非指导性的。
这两种上下文通过描述当前状态和期望的未来状态协同工作,使 Cursor 能够生成有价值的编码建议。
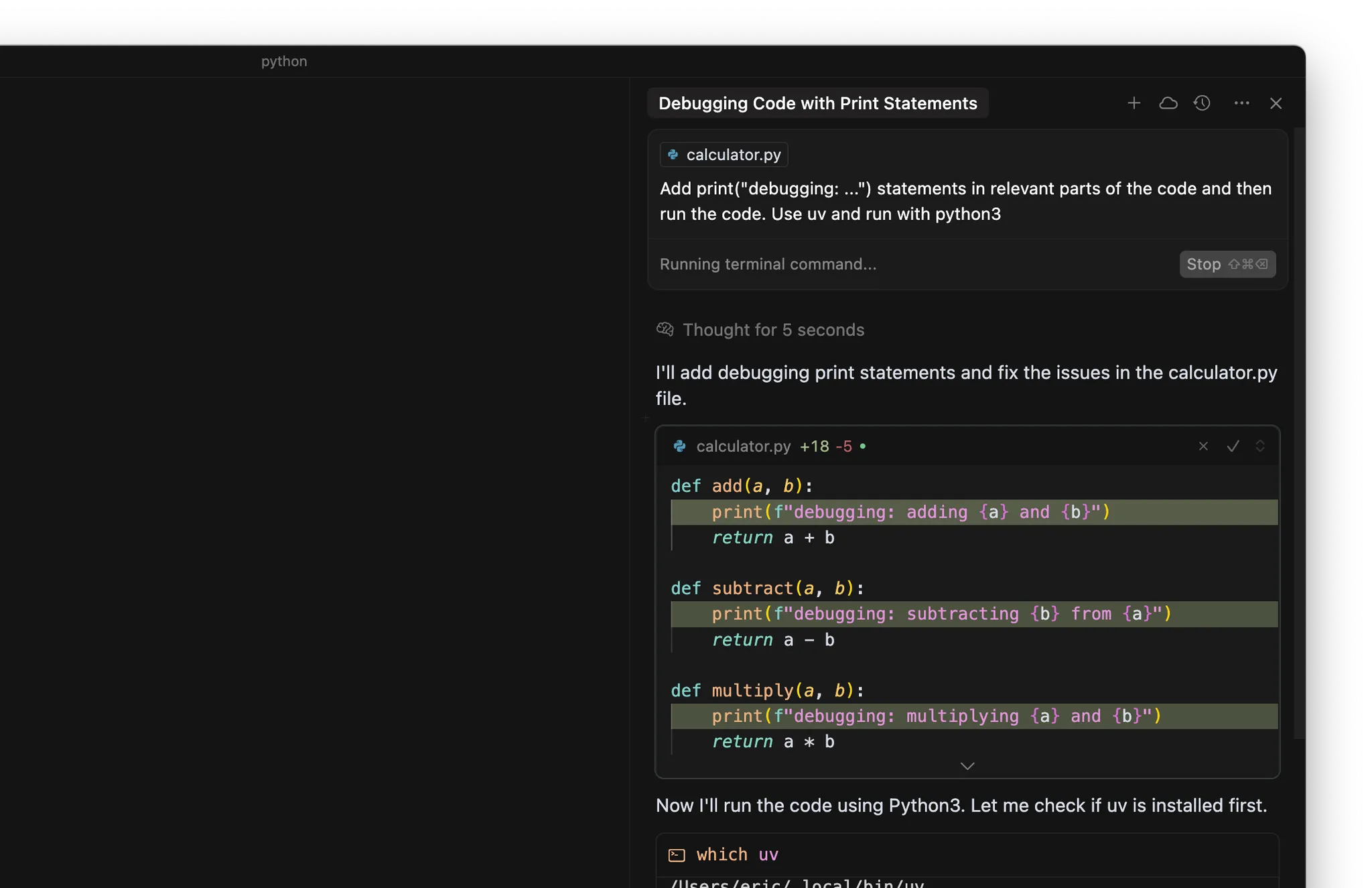
- 在代码相关位置添加
print("debugging: ...")语句 - 使用终端运行代码或测试
Agent 会读取终端输出并决定后续操作。核心思想是让 Agent 能够访问实际的运行时行为,而不仅仅是静态代码。
核心要点
- 上下文是 AI 高效编程的基础,由意图(你想实现的目标)和现有状态(当前代码现状)共同构成。同时提供这两者能帮助 Cursor 做出精准预测。
- 使用精准的 @ 符号上下文(@code、@file、@folder)来精确引导 Cursor,而非单纯依赖自动上下文收集机制。
- 将可复用的知识沉淀为团队规则,通过模型上下文协议(Model Context Protocol)扩展 Cursor 的能力边界,实现与外部系统的深度连接。
- 上下文不足会导致臆测或低效,而过多的无关上下文会稀释有效信号。需在两者间找到最佳平衡点以获得最优结果。