使用 GPU 的 Spaces
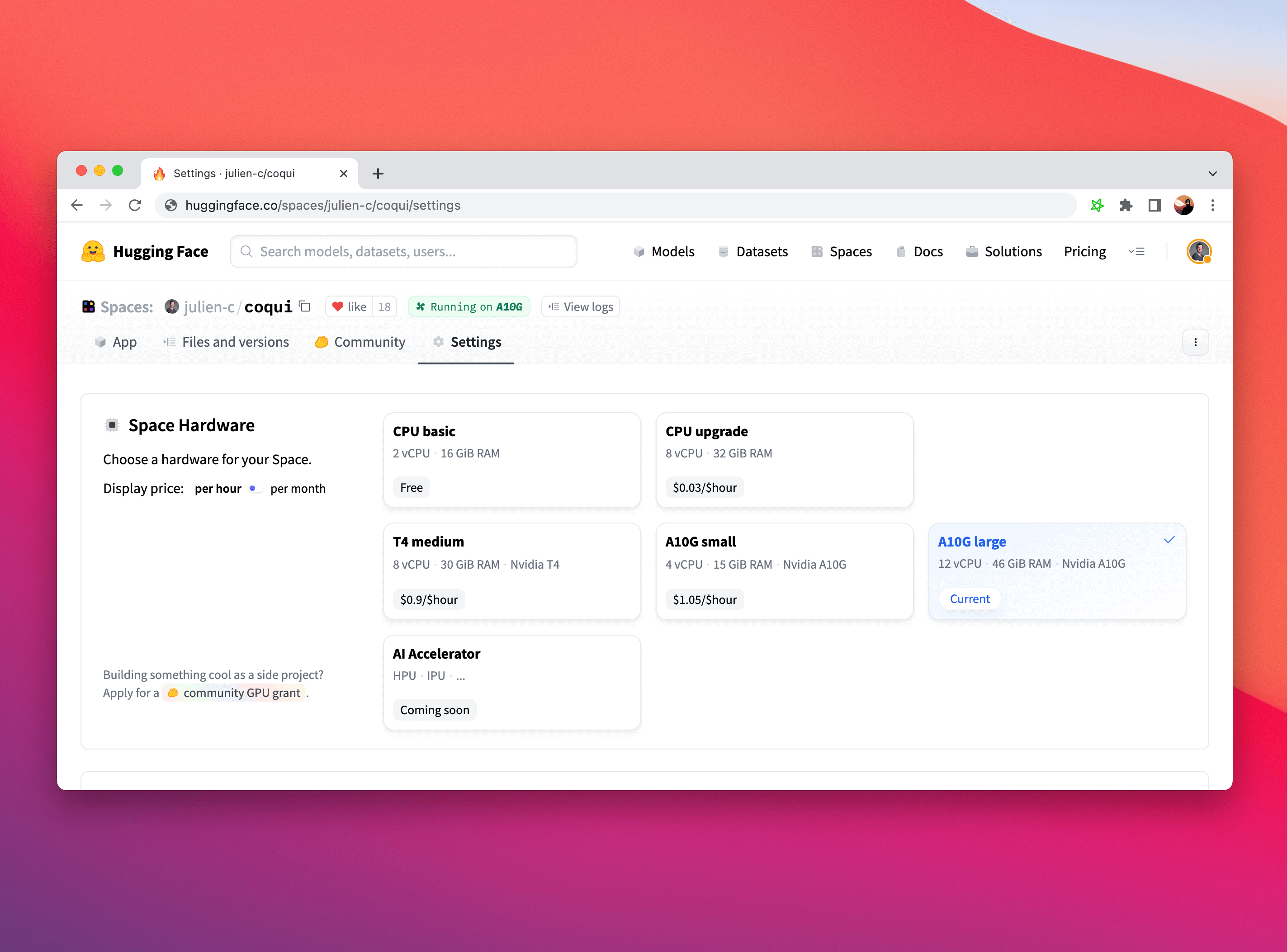
你可以通过 Space 页面顶部导航栏中的 Settings 按钮,将 Space 升级为使用 GPU 加速器。如果你正在为个人项目构建一个很酷的 Demo,还可以申请免费升级!

从长期来看,我们也希望支持非 GPU 硬件,比如 HPU、IPU 或 TPU。如果你有想要使用的特定 AI 硬件,欢迎在 huggingface.co 网站上告诉我们。
一旦 Space 在 GPU 上运行,你可以通过以下徽章直接看到它运行在哪种硬件上:
硬件规格
下列表格展示了各种升级选项的硬件规格。
CPU
| 硬件 | CPU | 内存 | GPU 内存 | 磁盘 | 每小时价格 |
|---|---|---|---|---|---|
| CPU Basic | 2 vCPU | 16 GB | - | 50 GB | Free! |
| CPU Upgrade | 8 vCPU | 32 GB | - | 50 GB | $0.03 |
GPU
| 硬件 | CPU | 内存 | GPU 内存 | 磁盘 | 每小时价格 |
|---|---|---|---|---|---|
| Nvidia T4 - small | 4 vCPU | 15 GB | 16 GB | 50 GB | $0.40 |
| Nvidia T4 - medium | 8 vCPU | 30 GB | 16 GB | 100 GB | $0.60 |
| 1x Nvidia L4 | 8 vCPU | 30 GB | 24 GB | 400 GB | $0.80 |
| 4x Nvidia L4 | 48 vCPU | 186 GB | 96 GB | 3200 GB | $3.80 |
| 1x Nvidia L40S | 8 vCPU | 62 GB | 48 GB | 380 GB | $1.80 |
| 4x Nvidia L40S | 48 vCPU | 382 GB | 192 GB | 3200 GB | $8.30 |
| 8x Nvidia L40S | 192 vCPU | 1534 GB | 384 GB | 6500 GB | $23.50 |
| Nvidia A10G - small | 4 vCPU | 14 GB | 24 GB | 110 GB | $1.00 |
| Nvidia A10G - large | 12 vCPU | 46 GB | 24 GB | 200 GB | $1.50 |
| 2x Nvidia A10G - large | 24 vCPU | 92 GB | 48 GB | 1000 GB | $3.00 |
| 4x Nvidia A10G - large | 48 vCPU | 184 GB | 96 GB | 2000 GB | $5.00 |
| Nvidia A100 - large | 12 vCPU | 142 GB | 80 GB | 1000 GB | $2.50 |
| Nvidia H100 | 23 vCPU | 240 GB | 80 GB | 3000 GB | $4.50 |
| 8x Nvidia H100 | 184 vCPU | 1920 GB | 640 GB | 24 TB | $36.00 |
通过代码配置硬件
你可以使用 huggingface_hub 以编程方式配置 Space 的硬件。这对于需要动态分配 GPU 的各种场景非常有用。
更多细节请查看这篇指南。
针对不同框架的要求
大多数 Space 在升级 GPU 后可以开箱即用,但有时你需要安装与内置 CUDA 驱动兼容的机器学习框架版本。请遵循本节指南,确保你的 Space 能充分利用更强的硬件。
PyTorch
你需要安装与内置 CUDA 驱动兼容的 PyTorch 版本。通常在 requirements.txt 中加入下面两行即可:
--extra-index-url https://download.pytorch.org/whl/cu113
torch
你可以在 app.py 中运行以下代码,并在 Space 日志中查看输出,以验证安装是否成功:
import torch
print(f"Is CUDA available: {torch.cuda.is_available()}")
# True
print(f"CUDA device: {torch.cuda.get_device_name(torch.cuda.current_device())}")
# Tesla T4
很多框架在检测到 GPU 可用时会自动使用 GPU,例如 🤗 transformers 的 Pipelines、fastai 等。在其他情况下,或者你直接使用 PyTorch 时,可能需要手动将模型和数据移动到 GPU,确保计算真正发生在加速卡上而不是 CPU 上。你可以使用 PyTorch 的 .to() 语法,例如:
model = load_pytorch_model()
model = model.to("cuda")
JAX
如果你使用 JAX,需要指定包含 CUDA 兼容包的 URL。请在 requirements.txt 中添加以下内容:
-f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
jax[cuda11_pip]
jaxlib
之后,你可以运行下面的代码并在 Space 日志中查看输出,验证安装是否成功:
import jax
print(f"JAX devices: {jax.devices()}")
# JAX devices: [StreamExecutorGpuDevice(id=0, process_index=0)]
print(f"JAX device type: {jax.devices()[0].device_kind}")
# JAX device type: Tesla T4
Tensorflow
默认安装的 tensorflow 应该会识别 CUDA 设备。只需在 requirements.txt 中添加 tensorflow,并在 app.py 中运行下面的代码,在 Space 日志中进行验证:
import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))
# [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
计费
Spaces 的计费基于硬件使用时间,并按分钟计算:只要 Space 在所请求的硬件上处于运行状态,你就会被计费,无论是否有用户访问。
在 Space 的生命周期中,仅在 Space 处于 Running 状态时才会计费。这意味着构建和启动阶段不产生费用。
如果正在运行的 Space 出现故障,将被自动挂起,计费也会停止。
运行在免费硬件上的 Spaces 在长时间(例如两天)未被访问时会自动暂停。升级后的 Space 默认会一直运行,即使没有访问。你可以在 Space 设置中配置自定义 “sleep time” 来改变这一行为。要停止 Space 的计费,可以将硬件切换回 CPU basic,或者将其暂停。
更多关于计费的信息,请参考 Hub 级别的计费章节。
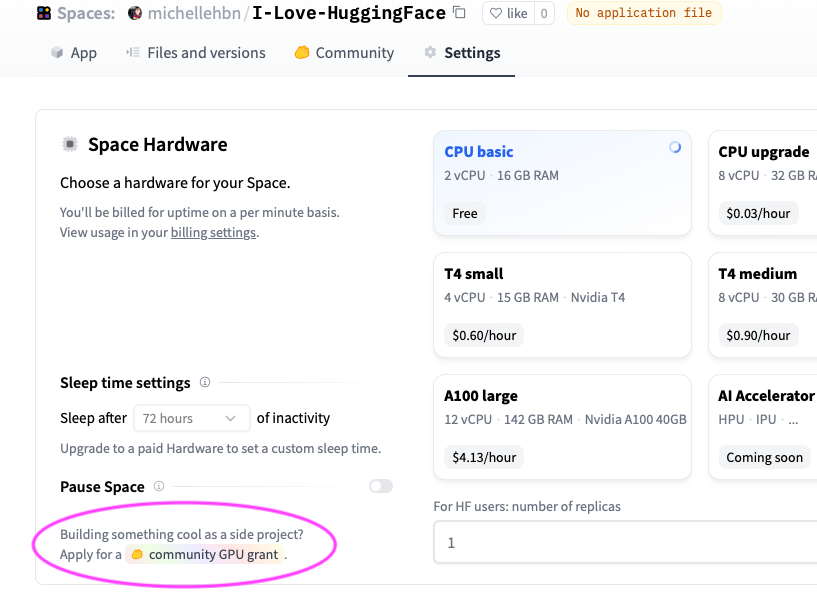
Community GPU Grants
你是否有一个很棒的 Space,但需要帮助分担 GPU 硬件升级成本?我们非常乐意帮助那些有创意的 Space,欢迎申请社区 GPU 资助,看看你的项目是否符合条件!你可以在 Space 硬件设置页面左下角的 “sleep time settings” 下找到申请入口:
设置自定义 sleep time
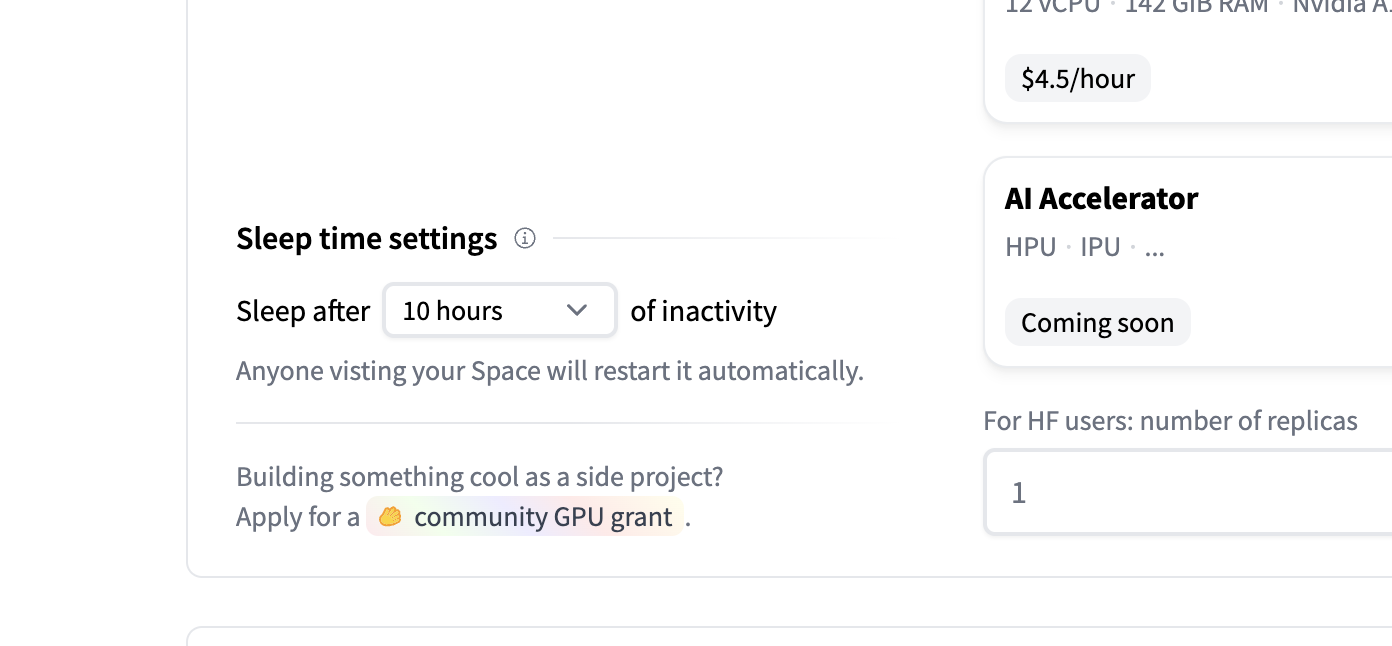
如果你的 Space 运行在默认的 cpu-basic 硬件上,当超过一定时间(当前为 48 小时)无人访问时,它会进入休眠。任何访问者都会自动重新唤醒该 Space。
如果你希望 Space 永不休眠,或者希望设置自定义的休眠时间,就需要升级到付费硬件。
默认情况下,升级后的 Space 永不休眠。不过,你可以使用此设置,让升级后的 Space 在长时间未使用时进入空闲状态(stopped),在休眠期间不会为升级硬件付费。一旦有新的访问者,Space 就会�被“唤醒”并重新启动。
下面的界面会出现在 Space 的硬件设置中:
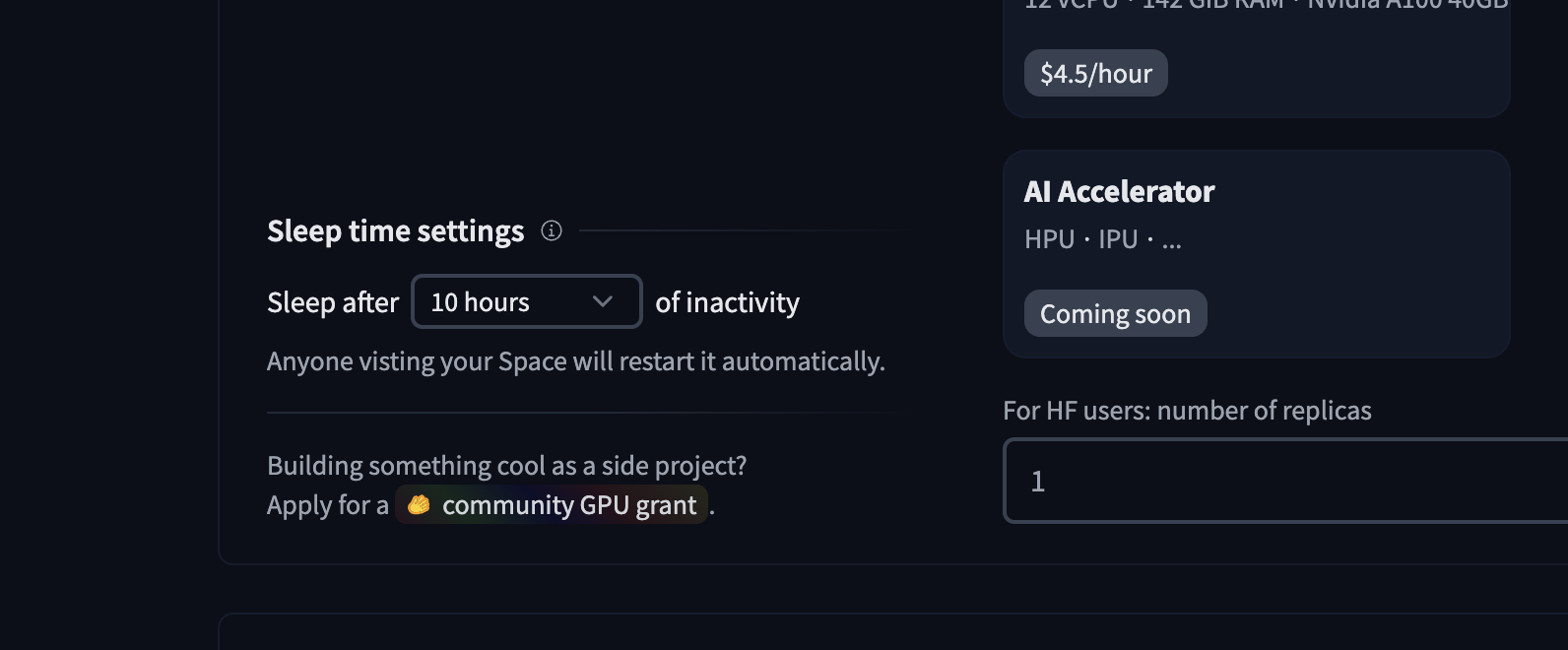
可用的选项如下:
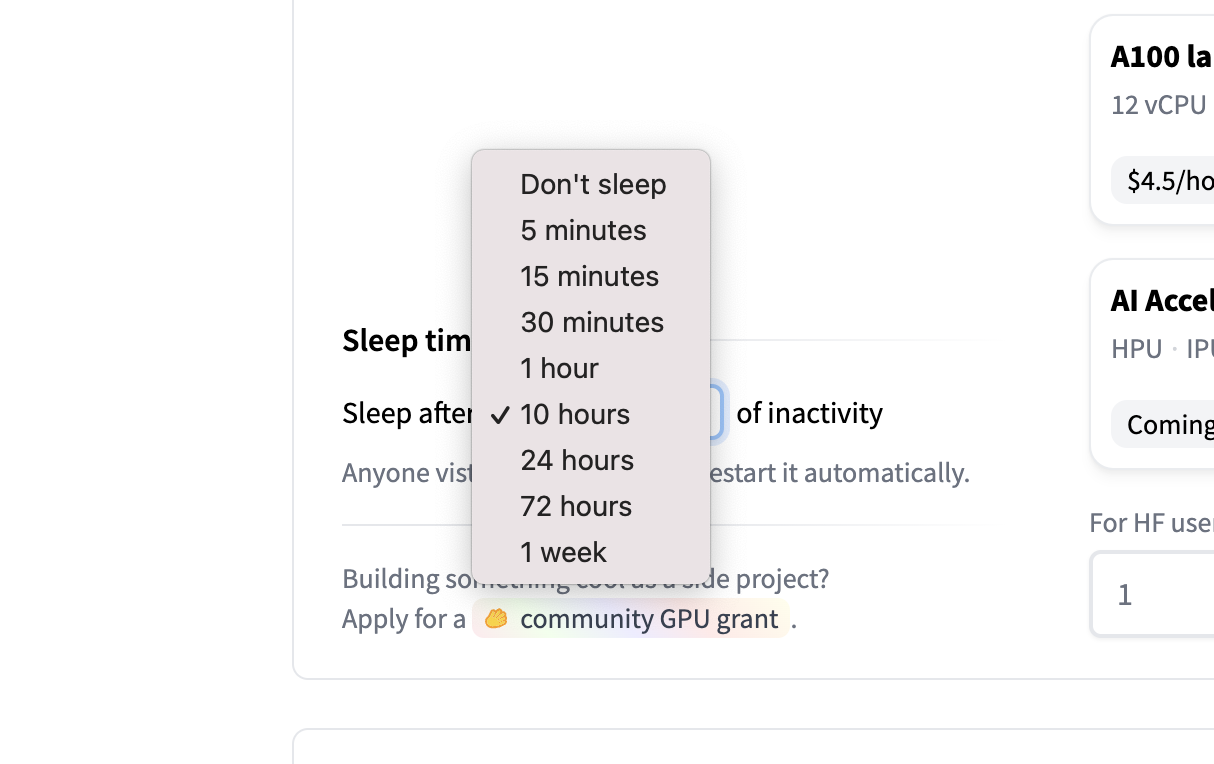
暂停 Space
你可以在仓库设置中将 Space 设为 pause。被暂停的 Space 处于挂起状态,不会使用任何资源,只有 Space 的拥有者可以手动重新启动。暂停期间不会产生费用。