将你的库与 Hub 集成
Hugging Face Hub 旨在促进机器学习模型、检查点和工件的共享。这项工作包括将 Hub 集成到社区中许多优秀的第三方库中。已经集成的一些库包括 spaCy、Sentence Transformers、OpenCLIP 和 timm 等。集成意味着用户可以直接从你的库中下载和上传文件到 Hub。我们希望你能集成你的库,与我们一起为所有人普及人工智能。
将 Hub 与你的库集成提供了许多好处,包括:
- 为你和你的用户提供免费的模型托管。
- 内置文件版本控制——即使对于大文件——由 Git-LFS 实现。
- 社区功能(讨论、拉取请求、点赞)。
- 使用你的库运行的所有模型的使用指标。
本教程将帮助你将 Hub 集成到你的库中,以便你的用户可以从 Hub 提供的所有功能中受益。
在开始之前,我们建议你创建一个 Hugging Face 账户,你可以从中管理你的仓库和文件。
如果你需要集成方面的帮助,请随时打开一个问题,我们很乐意帮助你。
实现
实现库与 Hub 的集成通常意味着提供内置方法来从 Hub 加载模型,并允许用户将新模型推送到 Hub。本节将介绍如何使用 huggingface_hub 库的基础知识。有关更深入的指导,请查看本指南。
安装
要将你的库与 Hub 集成,你需要添加 huggingface_hub 库作为依赖项:
pip install huggingface_hub
有关 huggingface_hub 安装的更多详细信息,请查看本指南。
在本指南中,我们将专注于 Python 库。如果你在 JavaScript 中实现了你的库,可以使用 @huggingface/hub。其余逻辑(即托管文��件、代码示例等)不依赖于代码语言。
npm add @huggingface/hub
用户成功安装 huggingface_hub 库后需要进行身份验证。最简单的身份验证方法是在机器上保存令牌。用户可以使用 login() 命令从终端执行此操作:
hf auth login
该命令会告诉他们是否已登录,并提示他们输入令牌。然后验证令牌并将其保存在他们的 HF_HOME 目录中(默认为 ~/.cache/huggingface/token)。与 Hub 交互的任何脚本或库在发送请求时都会使用此令牌。
或者,用户可以在 notebook 或脚本中使用 login() 以编程方式登录:
from huggingface_hub import login
login()
从 Hub 上的公共仓库下载文件时,身份验证是可选的。
从 Hub 下载文件
集成允许用户从 Hub 下载模型并直接从你的库中实例化它。这通常通过提供一个特定于你的库的方法(通常称为 from_pretrained 或 load_from_hf)来实现。要从 Hub 实例化模型,你的库必须:
- 从 Hub 下载文件。这就是我们现在要讨论的内容。
- 从这些文件实例化 Python 模型。
使用 hf_hub_download 方法从 Hub 上的仓库下载文件。下载的文件存储在缓存中:~/.cache/huggingface/hub。用户下次使用时不必重新下载文件,这为大文件节省了大量时间。此外,如果仓库更新了新版本的文件,huggingface_hub 将自动下载最新版本并将其存储在缓存中。用户不必担心手动更新文件。
例如,从 lysandre/arxiv-nlp 仓库下载 config.json 文件:
>>> from huggingface_hub import hf_hub_download
>>> config_path = hf_hub_download(repo_id="lysandre/arxiv-nlp", filename="config.json")
>>> config_path
'/home/lysandre/.cache/huggingface/hub/models--lysandre--arxiv-nlp/snapshots/894a9adde21d9a3e3843e6d5aeaaf01875c7fade/config.json'
config_path 现在包含下载文件的路径。保证文件存在且是最新的。
如果你的库需要下载整个仓库,请使用 snapshot_download。它将并行下载所有文件。返回值是包含下载文件的目录路径。
>>> from huggingface_hub import snapshot_download
>>> snapshot_download(repo_id="lysandre/arxiv-nlp")
'/home/lysandre/.cache/huggingface/hub/models--lysandre--arxiv-nlp/snapshots/894a9adde21d9a3e3843e6d5aeaaf01875c7fade'
存在许多选项可以从特定修订版下载文件、筛选要下载的文件、提供自定义缓存目录、下载到本地目录等。有关更多详细信息,请查看下载指南。
上传文件到 Hub
你可能还想提供一个方法,以便用户可以将自己的模型推送到 Hub。这允许社区构建与你的库兼容的模型生态系统。huggingface_hub 库提供了创建仓库和上传文件的方法:
create_repo在 Hub 上创建仓库。upload_file和upload_folder将文件上传到 Hub 上的仓库。
create_repo 方法在 Hub 上创建仓库。使用 repo_id 参数为你的仓库提供名称:
>>> from huggingface_hub import create_repo
>>> create_repo(repo_id="test-model")
'https://huggingface.co/lysandre/test-model'
当你检查你的 Hugging Face 账户时,你现在应该在你的命名空间下看到一个 test-model 仓库。
upload_file 方法将文件上传到 Hub。此方法需要以下内容:
- 要上传的文件路径。
- 仓库中的最终路径。
- 你希望推送文件的仓库。
例如:
>>> from huggingface_hub import upload_file
>>> upload_file(
... path_or_fileobj="/home/lysandre/dummy-test/README.md",
... path_in_repo="README.md",
... repo_id="lysandre/test-model"
... )
'https://huggingface.co/lysandre/test-model/blob/main/README.md'
如果你检查你的 Hugging Face 账户,你应该在仓库中看到该文件。
通常,库会将模型序列化到本地目录,然后一次性将整个文件夹上传到 Hub。这可以使用 upload_folder 完成:
>>> from huggingface_hub import upload_folder
>>> upload_folder(
... folder_path="/home/lysandre/dummy-test",
... repo_id="lysandre/test-model",
... )
有关如何上传文件的更多详细信息,请查看上传指南。
模型卡片
模型卡片是伴随模型并提供便捷信息的文件。在底层,模型卡片是带有附加元数据的简单 Markdown 文件。模型卡片对于可发现性、可重现性和共享至关重要!你可以在任何模型仓库中找到模型卡片作为 README.md 文件。有关如何创建良好模型卡片的更多详细信息,请参阅模型卡片指南。
如果你的库允许将模型推送到 Hub,建议生成一个带有预填充元数据(通常是 library_name、pipeline_tag 或 tags)和模型训练信息的最小模型卡片。这将有助于为使用你的库构建的所有模型提供标准化描述。
注册你的库
做得好!你现在应该有一个能够从 Hub 加载模型并最终推送新模型的库。下一步是确保你在 Hub 上的模型得到良好记录并与平台集成。为此,库可以在 Hub 上注册,这为用户带来了一些好处:
- 可以在模型页面上显示漂亮的标签(例如
KerasNLP而不是keras-nlp) - 每个模型页面都会添加指向你的库仓库和文档的链接
- 可以定义自定义下载计数规则
- 可以生成代码片段以显示如何使用你的库加载模型
要注册新库,请按照以下说明在此处打开拉取请求:
- 库 ID 应为小写并用连字符分隔(示例:
"adapter-transformers")。打开 PR 时确保保持字母顺序。 - 使用用户友好的大小写设置
repoName和prettyLabel(示例:DeepForest)。 - 使用指向库源代码的链接设置
repoUrl(通常是 GitHub 仓库)。 - (可选)使用指向库文档的链接设置
docsUrl。如果文档位于上面引用的 GitHub 仓库中,则无需设置两次。 - 将
filter设置为false。 - (可选)通过设置
countDownload定义如何计算下载次数。可以通过文件扩展名或文件名跟踪下载。确保不要重复计数。例如,如果加载模型需要 3 个文件,下载计数规则必须仅在 3 个文件中的 1 个上计数下载。否则,下载计数将被高估。 注意: 如果库使用默认配置文件之一(config.json、config.yaml、hyperparams.yaml、params.json和meta.yaml,请参见此处),则无需手动定义下载计数规则。 - (可选)定义
snippets以让用户知道如何快速实例化模型。更多详细信息如下。
在打开 PR 之前,请确保至少有一个模型在 https://huggingface.co/models?other=my-library-name 上被引用。如果没有,必须使用 library_name: my-library-name 更新相关模型的模型卡片元数据(请参见示例)。如果你不是 Hub 上模型的所有者,请打开 PR(请参见示例)。
这是为 VFIMamba 添加集成的最小示例。
代码片段
我们建议添加代码片段来解释如何在下游库中使用模型。
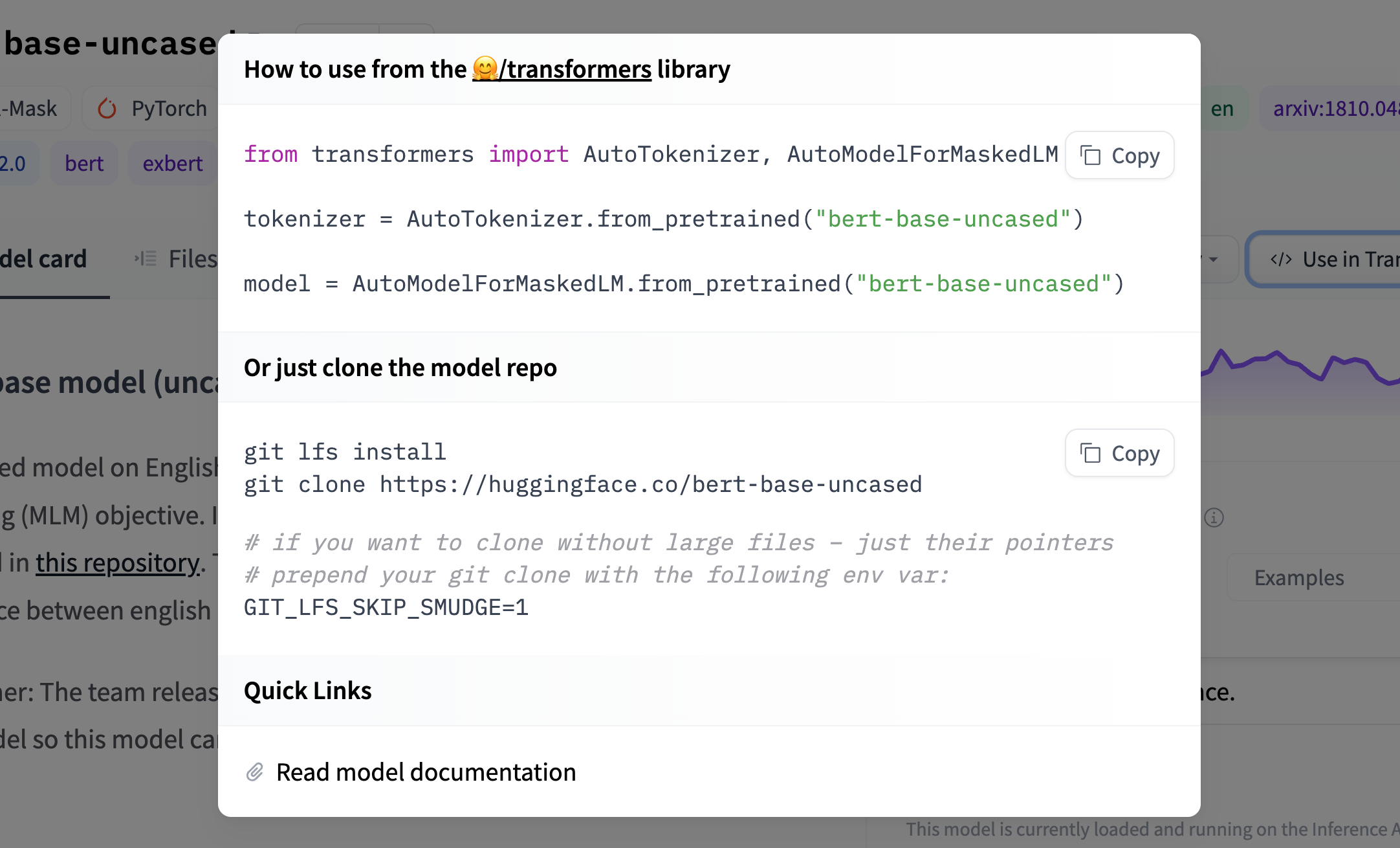
要添加代码片段,你应该使用模型的说明更新 model-libraries-snippets.ts 文件。例如,Asteroid 集成包含一个简短的代码片段,说明如何加载和使用 Asteroid 模型:
const asteroid = (model: ModelData) =>
`from asteroid.models import BaseModel
model = BaseModel.from_pretrained("${model.id}")`;
这样做还会为你的模型添加标签,以便用户可以快速识别来自你的库的模型。
一旦你的代码片段已添加到 model-libraries-snippets.ts,你可以按照上述说明在 model-libraries.ts 中引用它。