在 Hugging Face 使用 SpeechBrain
speechbrain 是一个开源的一体化音频/语音对话工具包。目标是创建一个单一、灵活且用户友好的工具包,可用于轻松开发最先进的语音技术,包括语音识别、说话人识别、语音增强、语音分离、语言识别、多麦克风信号处理等系统。
在 Hub 上探索 SpeechBrain
你可以通过在模型页面左侧筛选来找到 speechbrain 模型。
Hub 上的所有模型都配备了以下功能:
- 自动生成的模型卡片,包含简要描述。
- 有助于可发现性的元数据标签,包含语言、许可证、论文等信息。
- 一个交互式小部件,你可以直接在浏览器中使用模型。
- 允许进行推理请求的推理 API。
使用现有模型
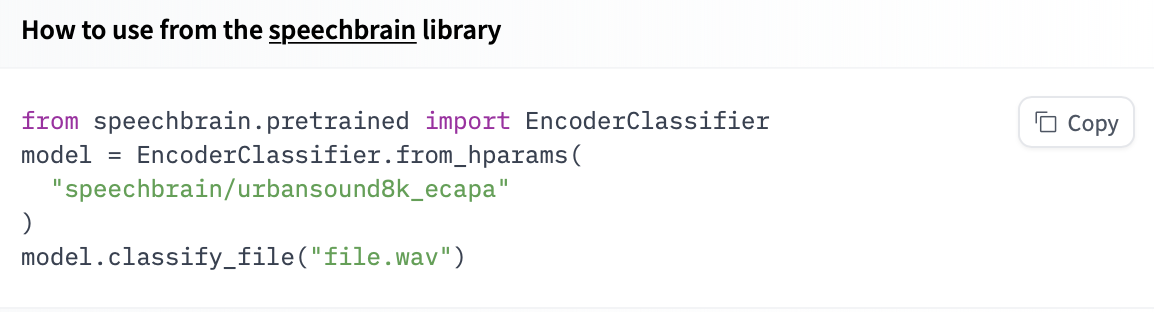
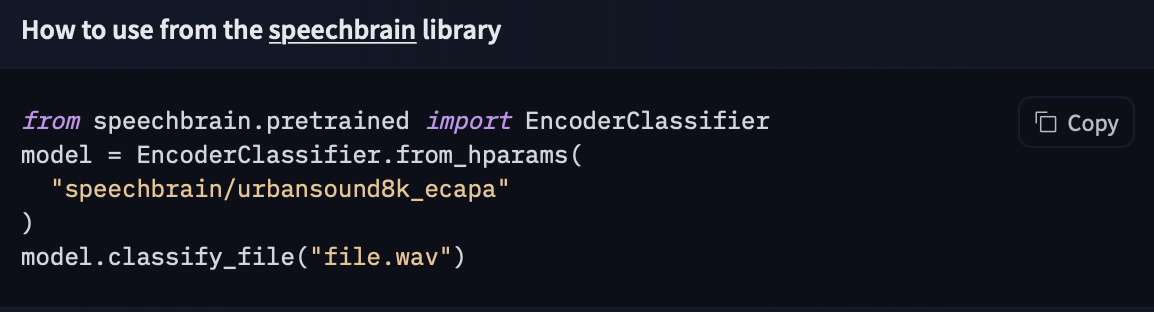
speechbrain 提供不同的接口来管理不同任务的预训练模型,例如 EncoderClassifier、EncoderClassifier、SepformerSeperation 和 SpectralMaskEnhancement。这些类有一个 from_hparams 方法,你可以使用它从 Hub 加载模型
以下是在城市声音中进行声音识别的推理示例。
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(
source="speechbrain/urbansound8k_ecapa"
)
out_prob, score, index, text_lab = classifier.classify_file('speechbrain/urbansound8k_ecapa/dog_bark.wav')
如果你想查看如何加载特定模型,可以点击 Use in speechbrain,你将获得一个可用的代码片段来加载它!