在 Hugging Face 使用 🤗 transformers
🤗 transformers 是由 Hugging Face 和社区维护的库,用于 PyTorch、TensorFlow 和 JAX 的最先进机器学习。它提供了数千个预训练模型,用于执行文本、视觉和音频等不同模态的任务。我们有点偏颇,但我们真的很喜欢 🤗 transformers!
在 Hub 上探索 🤗 transformers
Hub 中有超过 630,000 个 transformers 模型,你可以通过在模型页面左侧筛选来找到它们。
你可以找到用于许多不同任务的模型:
- 从上下文中提取答案(问答)。
- 从大文本创建摘要(摘要生成)。
- 分类文本(例如,是否为垃圾邮件,文本分类)。
- 使用 GPT 等模型生成新文本(文本生成)。
- 识别句子中的词性(动词、主语等)或实体(国家��、组织等)(词元分类)。
- 将音频文件转录为文本(自动语音识别)。
- 分类音频文件中的说话人或语言(音频分类)。
- 检测图像中的对象(目标检测)。
- 分割图像(图像分割)。
- 进行强化学习(强化学习)!
如果你想在不下载模型的情况下测试它们,可以直接在浏览器中试用模型,这要归功于浏览器内小部件!

Transformers 仓库文件
Transformers 模型仓库通常包含模型文件和预处理器文件。

模型
-
config.json文件存储有关模型架构的详细信息,例如隐藏层数、词汇表大小、注意力头数、每个头的维度等。此元数据是模型蓝图。 -
model.safetensors文件存储模型的预训练层和权重。对于大型模型,safetensors 文件被分片以限制加载它所需的内存。浏览model.safetensors.index.json文件以查看模型权重从哪个 safetensors 文件加载。{
"metadata": {
"total_size": 16060522496
},
"weight_map": {
"lm_head.weight": "model-00004-of-00004.safetensors",
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
...
}
}你还可以通过点击模型卡片上的 ↗ 按钮来可视化此映射。

Safetensors 是一种更安全、更快的序列化格式——与 pickle 相比——用于存储模型权重。你可能会遇到以
bin、pth或ckpt等格式序列化的权重,但safetensors作为更好的替代方案在模型生态系统中越来越被采用。 -
模型还可能有一个
generation_config.json文件,该文件存储有关如何生成文本的详细信息,例如是否采样、要采样的顶级令牌、温度以及用于开始和停止生成的特殊令牌。
预处理器
tokenizer_config.json文件存储模型添加��的特殊令牌。这些特殊令牌向模型发出许多信号,例如句子的开头、聊天模板的特定格式或指示图像。此文件还显示模型可以接受的最大输入序列长度、预处理器类及其返回的输出。tokenizer.json文件存储模型学习到的词汇表。special_tokens_map.json是特殊令牌的映射。例如,在 Llama 3.1-8B-Instruct 中,字符串令牌的开头是"<|begin_of_text|>"。
对于其他模态,tokenizer_config.json 文件被 preprocessor_config.json 替换。
使用现有模型
所有 transformer 模型都只需一行代码即可使用!根据你想要使用它们的方式,你可以使用 pipeline 函数的高级 API,或者使用 AutoModel 获得更多控制。
# 使用 pipeline,只需指定任务和 Hub 中的模型 ID。
from transformers import pipeline
pipe = pipeline("text-generation", model="distilbert/distilgpt2")
# 如果你想要更多控制,你需要定义分词器和模型。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
你还可以从特定版本(基于提交哈希、标签名称或分支)加载模型,如下所示:
model = AutoModel.from_pretrained(
"julien-c/EsperBERTo-small", revision="v2.0.1" # 标签名称,或分支名称,或提交哈希
)
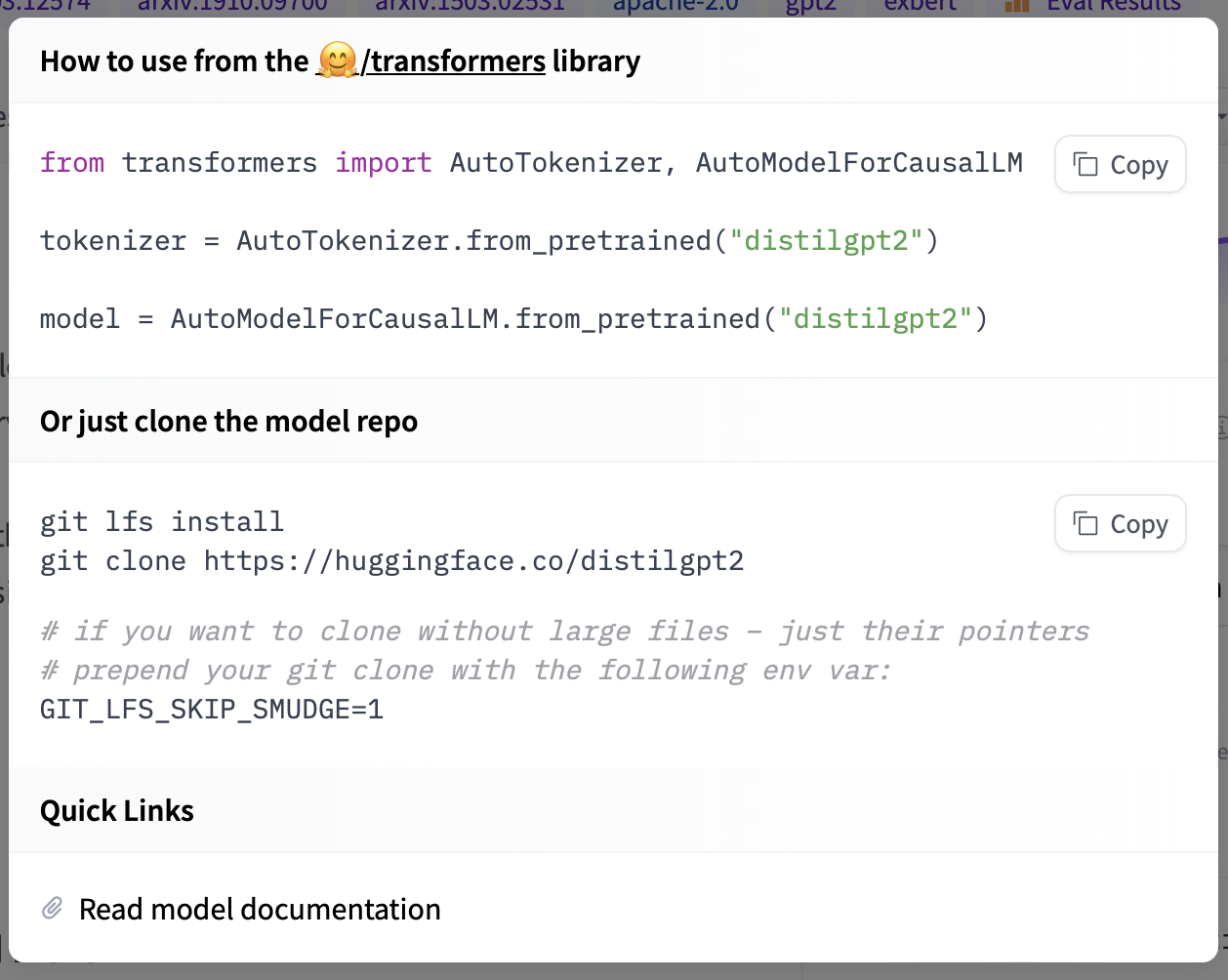
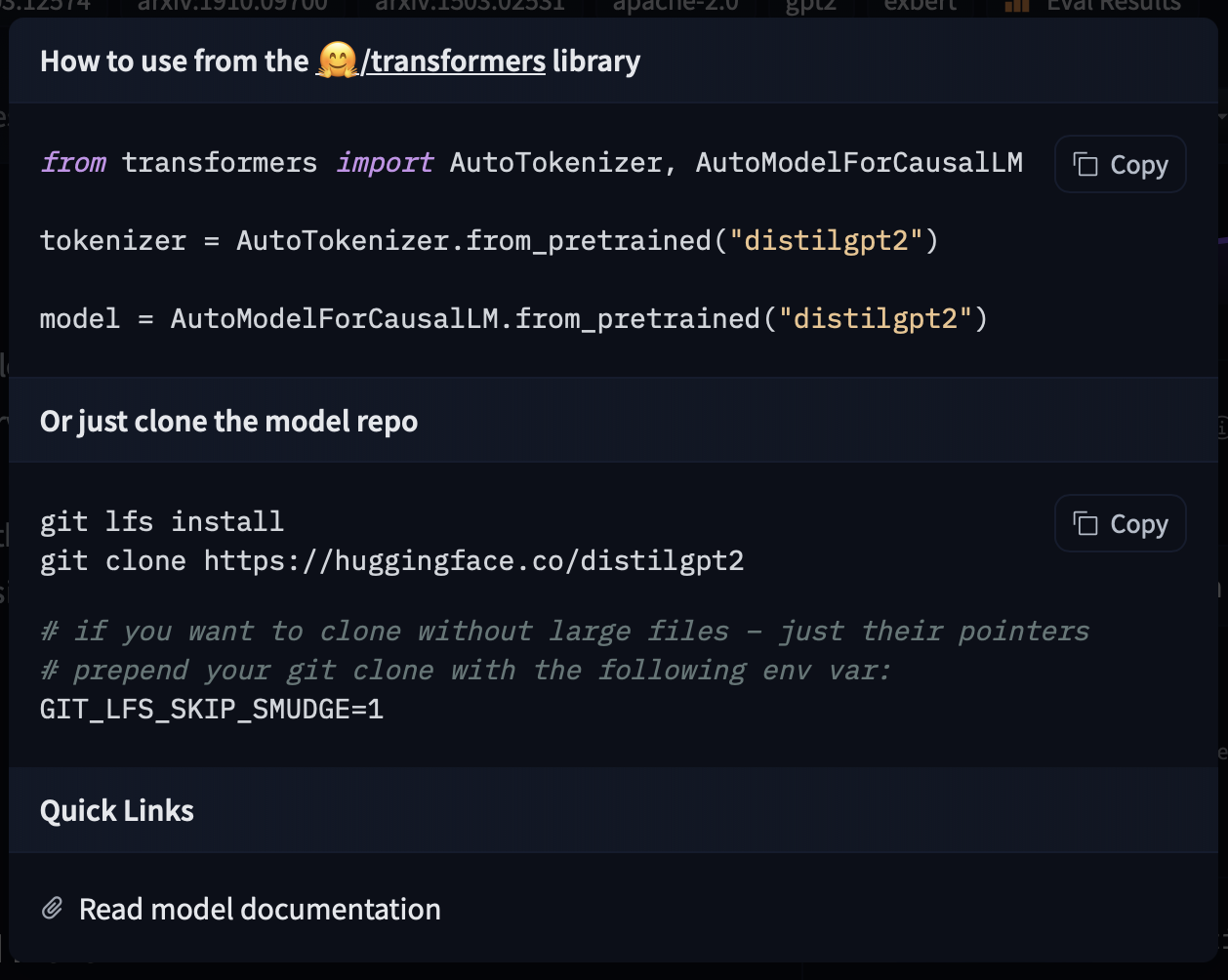
如果你想查看如何加载特定模型,可以点击 Use in Transformers,你将获得一个可用的代码片段来加载它!如果你需要有关模型架构的更多信息,还可以点击代码片段底部的"Read model documentation"。
分享你的模型
要了解有关使用 transformers 分享模型的所有信息,请前往官方文档中的分享模型指南。
transformers 中的许多类,例如模型和分词器,都有一个 push_to_hub 方法,可以轻松将文件上传到仓库。
# 将模型推送到你自己的账户
model.push_to_hub("my-awesome-model")
# 推送你的分词器
tokenizer.push_to_hub("my-awesome-model")
# 训练后推送所有内容
trainer.push_to_hub()
你还可以做更多事情,因此我们建议查看分享模型指南。